
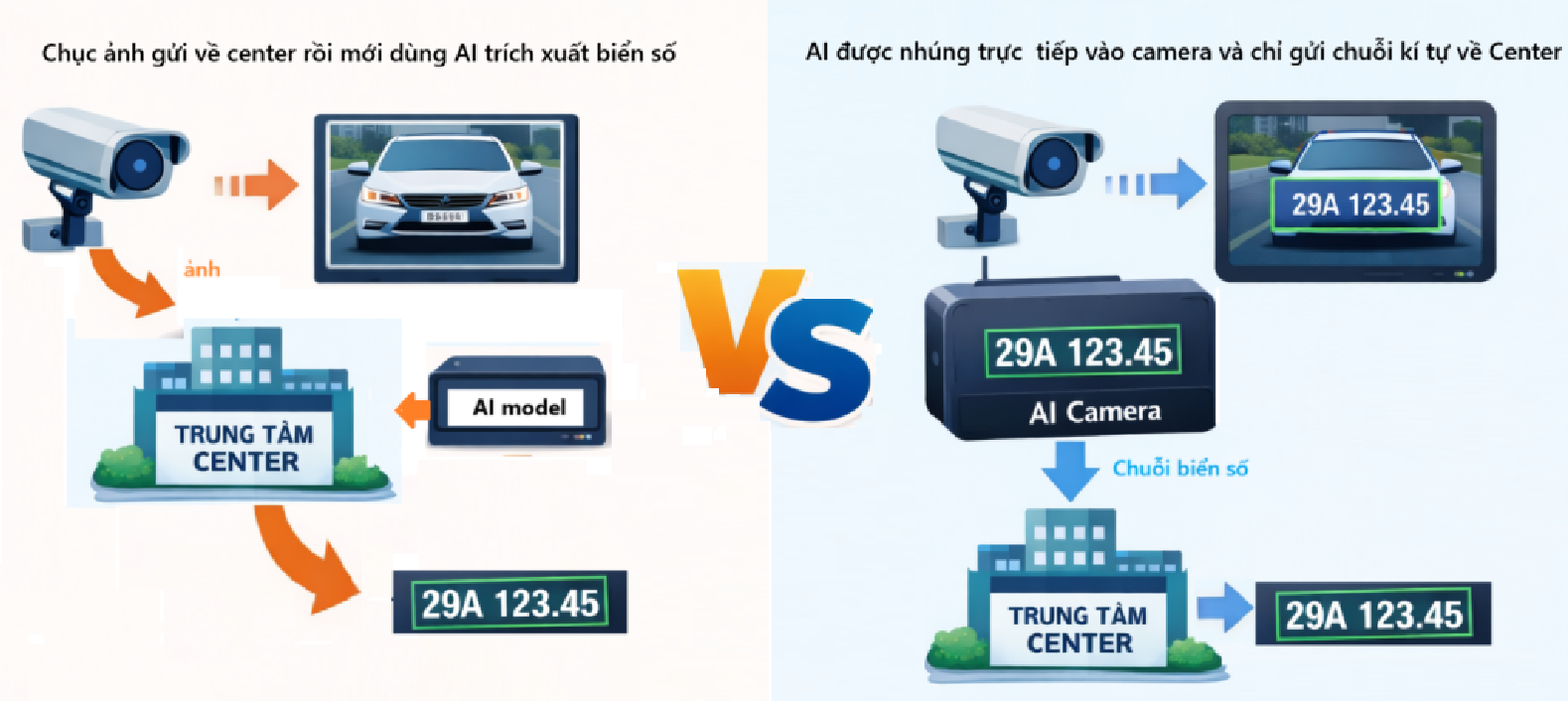
Bạn muốn thực hiện một dự án EdgeAI nhưng lại lo lắng về cấu hình phần cứng hạn chế? Bạn nghĩ tích hợp trí tuệ nhân tạo lên vi điều khiển là điều “bất khả thi”? Hãy để Cộng đồng kỹ thuật TAPIT trả lời những câu hỏi trên tại sự kiện WTTC34! Sự kiện lần này sẽ mang đến cái nhìn thực tế và quy trình tham khảo để bạn tự tay đưa các mô hình AI vào dòng chip ESP32 quen thuộc.
📢 Chủ đề:
Tích hợp AI cho ESP32 đơn giản hơn bạn tưởng!
Được trình bày bởi: Võ Văn Bưu, Lương Như Quỳnh.
Tài liệu được sử dụng tại sự kiện TAPIT WTTC34.
1. Tổng quan bài toán giải pháp
Giữa dòng xe ra vào không ngừng, mỗi tấm biển số chỉ xuất hiện trong vài khoảnh khắc ngắn ngủi rồi biến mất. Nhưng nếu có một “người gác cổng” thầm lặng, luôn quan sát, ghi nhớ và suy luận ngay tại chỗ thì sao?
Trong buổi trò chuyện hôm nay, chúng ta sẽ cùng bước vào hành trình tích hợp trí tuệ nhân tạo ngay tại thiết bị biên, nơi một lõi MCU nhỏ bé – ESP32-CAM không chỉ chụp ảnh, mà còn nhìn, hiểu và quyết định. Không cần gửi dữ liệu lên đám mây, AI được triển khai trực tiếp ở biên để trích xuất và nhận diện biển số xe theo thời gian thực, phục vụ bài toán theo dõi xe ra vào tại các vị trí đỗ nơi camera được lắp đặt.
Hình 1 .Ví dụ về trích xuất biển số xe
Hình 2. Sơ đồ tổng quan giải pháp
Bưu và Quỳnh sẽ cùng các bạn đi xuyên suốt toàn bộ quy trình: từ huấn luyện một mô hình gọn nhẹ trên nền tảng Edge Impulse, tối ưu cho tài nguyên hạn chế của thiết bị biên, cho đến nhúng mô hình trực tiếp vào MCU ESP32-CAM. Tại đây, camera trở thành nguồn dữ liệu sống, từng khung hình được thu nhận, tiền xử lý và đưa vào mô hình để trích xuất thông tin biển số xe, biến những hình ảnh thoáng qua thành dữ liệu có ý nghĩa cho hệ thống bãi đỗ xe thông minh.
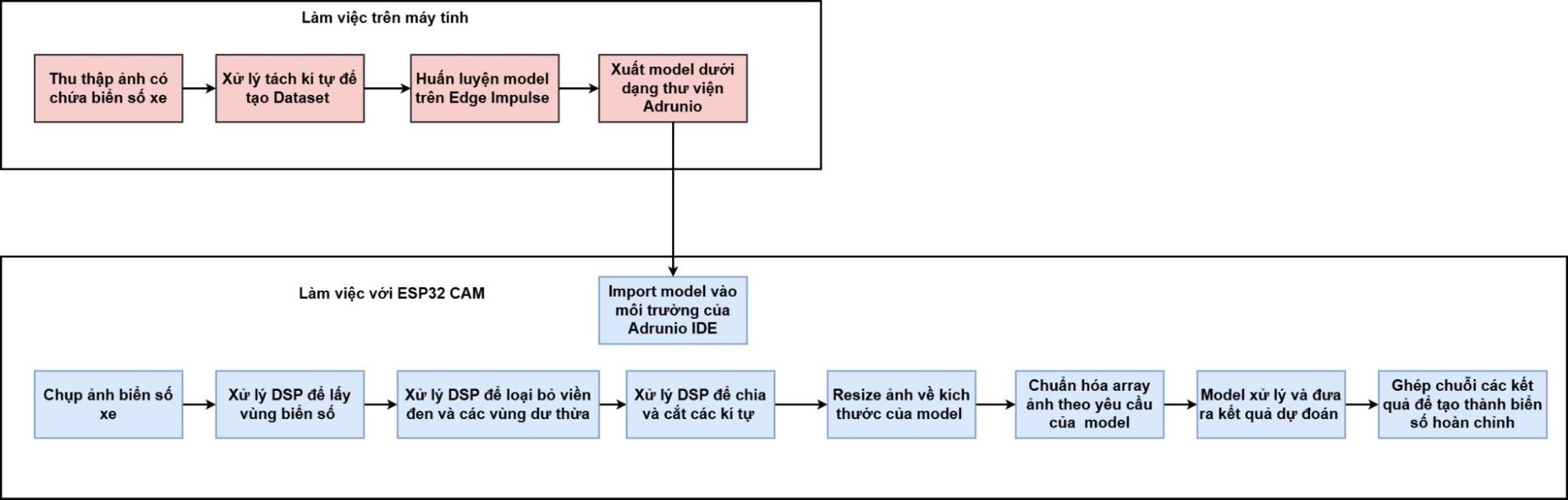
2. Quy trình huấn luyện model
Hình 3. Sơ đồ quy trình huấn luyện và triển khai mô hình nhận diện ký tự biển số xe trên Edge Impulse
2.1. Chuẩn bị cơ sở dữ liệu biển số xe
Quy trình chuẩn bị dữ liệu cho mô hình nhận diện ký tự biển số xe được thực hiện một cách bài bản và có hệ thống. Trước hết, chúng tôi tiến hành thu thập một tập dữ liệu lớn gồm các hình ảnh chứa biển số xe từ nhiều nguồn khác nhau trên internet, bao gồm các bộ dữ liệu công khai, hình ảnh thực tế từ camera giao thông cũng như các nguồn mở đáng tin cậy. Các hình ảnh này thường bao gồm toàn bộ phương tiện hoặc ít nhất là vùng biển số xe hiển thị rõ ràng, đồng thời đi kèm thông tin nhãn biển số gốc để phục vụ cho các bước xử lý tiếp theo.
Tiếp theo, chúng tôi sử dụng Python kết hợp với thư viện xử lý ảnh OpenCV để thực hiện các bước tiền xử lý. Cụ thể, hệ thống tiến hành phát hiện và trích xuất vùng biển số xe từ ảnh gốc, sau đó tách từng ký tự riêng lẻ trên biển số. Mỗi ký tự sau khi được tách sẽ được xử lý để cải thiện chất lượng ảnh, bao gồm điều chỉnh độ sáng và độ tương phản, chuyển sang ảnh xám và chuẩn hóa kích thước về 28 × 28 pixel. Việc chuẩn hóa này giúp đảm bảo tính đồng nhất của dữ liệu đầu vào và phù hợp với yêu cầu của mô hình học máy.
Cuối cùng, các ảnh ký tự sau khi xử lý được sắp xếp và lưu trữ vào các thư mục riêng biệt theo từng lớp ký tự, chẳng hạn thư mục “0” chứa các ảnh của chữ số 0, thư mục “A” chứa các ảnh ký tự A. Cách tổ chức này giúp tập dữ liệu trở nên gọn gàng, dễ quản lý và sẵn sàng để tải lên nền tảng huấn luyện, phục vụ cho quá trình xây dựng mô hình nhận diện ký tự biển số xe một cách hiệu quả.

Hình 4. Xử lí tách kí tự để tạo dataset
Hình 5. Các kí tự sau khi cắt được sắp xếp và lưu trữ vào folder riêng biệt
Tổng quan về tập dữ liệu:
- Tổng số hình ảnh: 250 hình ảnh cho mỗi chữ cái (tổng cộng 3000 hình ảnh cho 12 kí tự)
- Định dạng hình ảnh: .jpg, miền grayscale
- Độ phân giải hình ảnh: 28×28 pixels
- Phân chia hình ảnh để huấn luyện AI:
- Training: 80%
- Testing: 20%
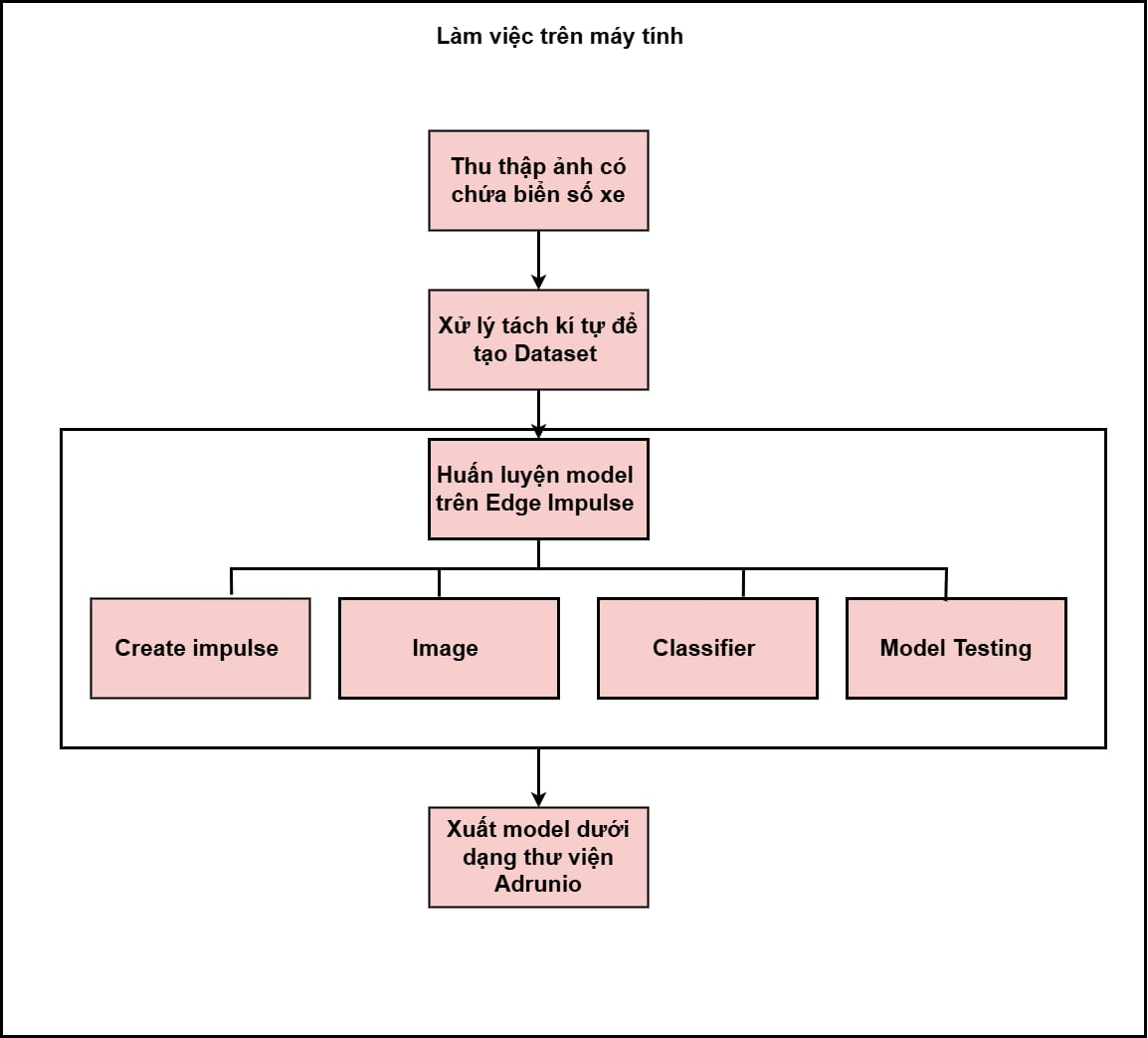
2.2. Huấn luyện mô hình AI trên Edge Impulse
Bước 1. Sau khi đăng ký account và tạo project mới thành công, chúng ta sẽ tiến hành upload dữ liệu lên dự án đó. Có thể upload ảnh và label bằng nhiều cách. Trong dự án này, chúng ta sử dụng phương pháp tải dữ liệu có sẵn từ máy tính.
Hình 6. Giao diện chính của data acquisition
Bước 2. Tải dữ liệu có sẵn (Add existing data), chọn Upload data để mở cửa sổ tải tệp.
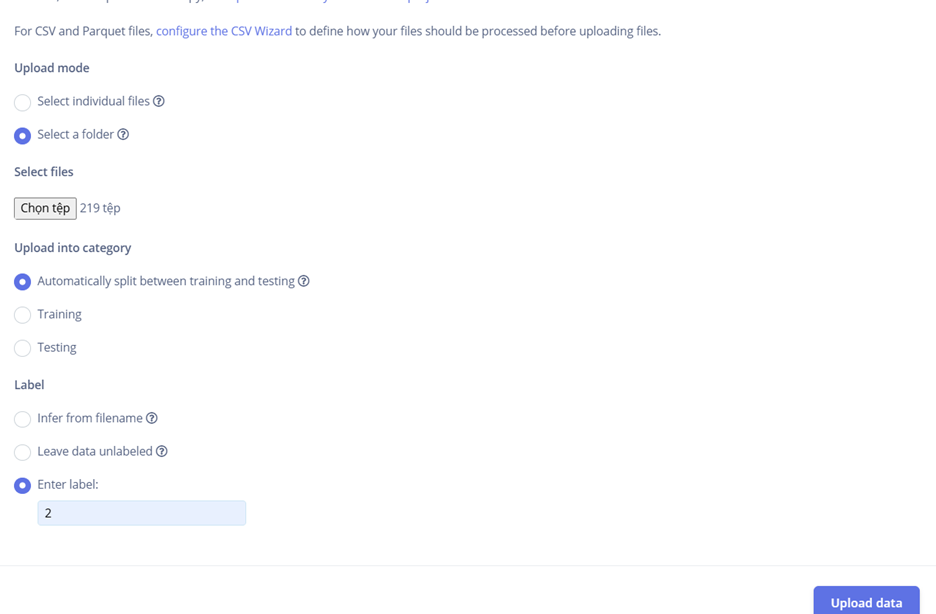
Hình 7. Upload dữ liệu có sẵn từ máy tính lên Edge Impulse
Tại mục Select a folder, chọn thư mục chứa toàn bộ các ảnh ký tự đã được chuẩn bị sẵn trên máy tính (cấu trúc thư mục theo từng lớp như folder “0”, “1”, …, “A”, “B”, …). Việc tải dữ liệu theo thư mục sẽ giúp tiết kiệm rất nhiều thời gian thay vì phải chọn và tải từng ảnh riêng lẻ.
Sau khi mở thư mục cần tải và chọn các file ảnh bên trong, bạn tiến hành tải lên (upload). Trong quá trình này, Edge Impulse cho phép chọn cách phân chia dữ liệu: khuyến nghị chọn Automatically split between training and testing để nền tảng tự động phân bổ ngẫu nhiên một phần dữ liệu vào tập huấn luyện (training) và phần còn lại vào tập kiểm tra (testing), thường theo tỷ lệ hợp lý như 80% training và 20% testing. Bạn cũng có thể chọn Manual split nếu muốn tự kiểm soát, hoặc chọn Training (toàn bộ ảnh tải lên sẽ thuộc tập train) hoặc Testing (toàn bộ ảnh tải lên sẽ thuộc tập test) tùy theo nhu cầu.
Để tăng tốc độ xử lý và tránh phải gán nhãn thủ công từng ảnh, nên sử dụng tùy chọn Enter label: nhập trực tiếp nhãn chung cho toàn bộ các ảnh trong đợt tải đó (ví dụ: nhập “2” nếu đang tải thư mục chứa tất cả ảnh ký tự số 2, hoặc nhập “A” cho thư mục chứa ký tự chữ A). Edge Impulse sẽ tự động gán nhãn này cho mọi ảnh trong thư mục, giúp quá trình chuẩn bị dữ liệu trở nên nhanh chóng và thuận tiện hơn rất nhiều. Lặp lại các bước này cho từng thư mục tương ứng với từng lớp ký tự cho đến khi toàn bộ dataset được tải lên hoàn chỉnh.
Hình 8. Hoàn tất việc upload ảnh
Bước 3. Impulse design – thiết lập các block và cấu hình chi tiết nhiều block
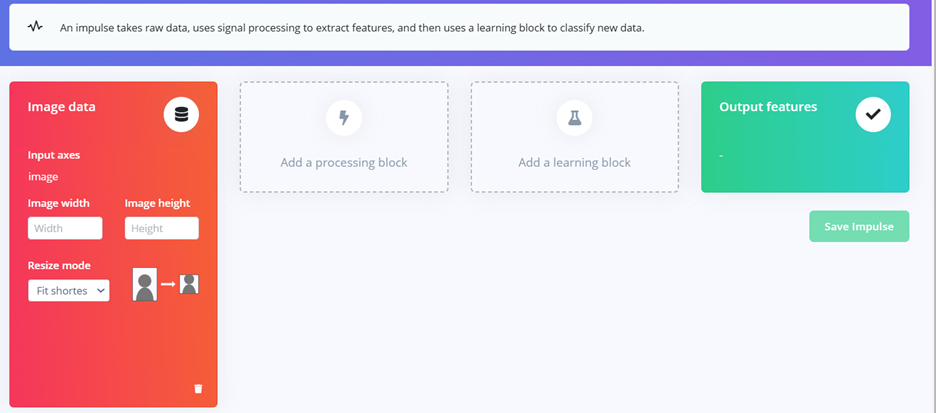
Hình 9. Cấu hình các block trong Impulse design
Đầu tiên ta setting Image data bằng cách đặt lại size và chọn resize mode, trong dự án này thì chúng tôi chọn size 28×28 pixels và fit shortest axis.
– Image size: Trong project này, kích thước ảnh được đặt là 28 × 28 pixels. Kích thước nhỏ giúp giảm số lượng tham số của mô hình và tăng tốc độ huấn luyện và suy luận.
– Resize mode: chọn Fit shortest axis để anh sẽ được resize sao cho cạnh ngắn nhất vừa khớp với kích thước yêu cầu. Phần dư của ảnh sẽ được cắt hoặc padding hợp lý, giúp hạn chế méo hình và giữ lại đặc trưng quan trọng của chữ số/ký tự.
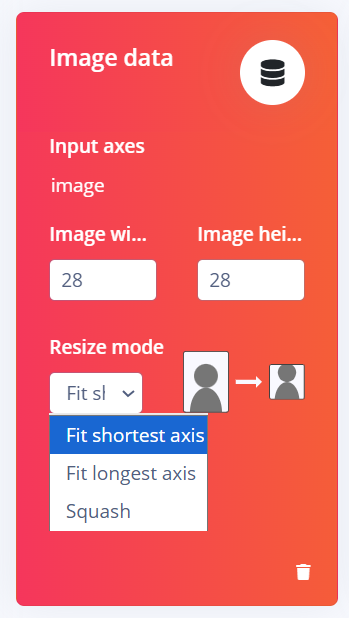
Hình 10. Đặt lại size cho hình ảnh
Add a processing block trong quá trình thiết kế Impulse của Edge Impulse, nơi người dùng xác định cách dữ liệu ảnh sẽ được xử lý trước khi đưa vào mô hình huấn luyện. Trong project training ảnh, khối Image được lựa chọn vì đây là khối xử lý chuyên biệt cho dữ liệu hình ảnh và được hệ thống khuyến nghị. Khối này có nhiệm vụ tiền xử lý ảnh như chuẩn hóa giá trị pixel, thay đổi kích thước ảnh về cùng một chuẩn và tối ưu dữ liệu đầu vào, giúp giảm sự khác biệt giữa các ảnh trong tập dữ liệu. Nhờ quá trình tiền xử lý này, mô hình học máy có thể tập trung vào việc học các đặc trưng quan trọng của hình ảnh thay vì bị ảnh hưởng bởi nhiễu hoặc sự không đồng nhất về kích thước và chất lượng ảnh. Các processing block khác như EEG hay Raw Data được hiển thị nhưng không phù hợp với bài toán nhận dạng ảnh, do đó không được sử dụng trong project. Việc lựa chọn đúng processing block ở bước này góp phần nâng cao hiệu quả huấn luyện và độ chính xác của mô hình phân loại ảnh.
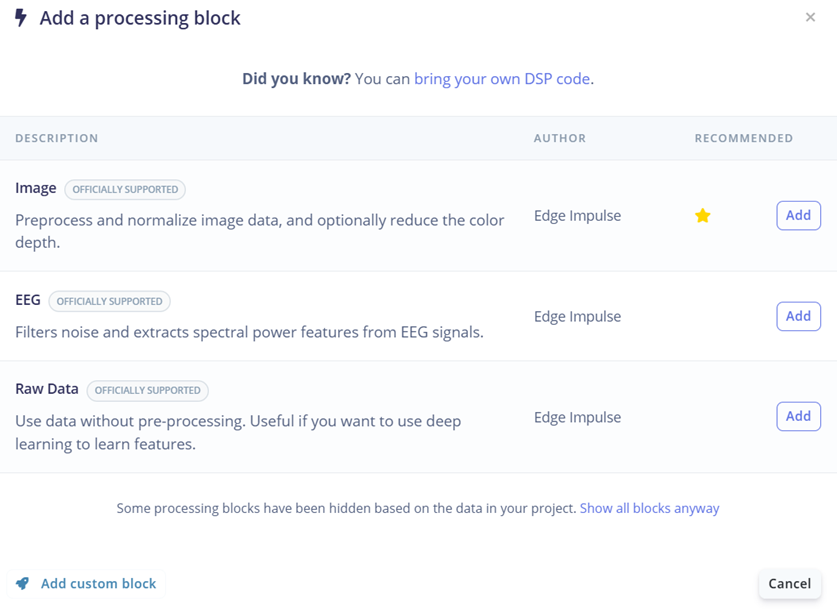
Hình 11. Add a processing block trong quá trình thiết kế Impulse
Trong project huấn luyện ảnh, Learning block – Classification được chọn nhằm thực hiện nhiệm vụ phân loại các đối tượng trong ảnh. Khối Classification cho phép mô hình học các đặc trưng và quy luật từ tập dữ liệu huấn luyện, sau đó áp dụng những kiến thức này để dự đoán nhãn của các ảnh mới. Đây là lựa chọn phù hợp cho các bài toán nhận dạng chữ số và ký tự, khi mỗi ảnh đầu vào chỉ thuộc về một lớp xác định. Các learning block khác như Transfer Learning (Images), Regression hay Visual Anomaly Detection cũng được cung cấp, tuy nhiên không phù hợp với mục tiêu phân loại cơ bản của project. Việc lựa chọn đúng learning block giúp đảm bảo mô hình được huấn luyện theo đúng mục tiêu, từ đó nâng cao độ chính xác và hiệu quả của hệ thống nhận dạng ảnh.
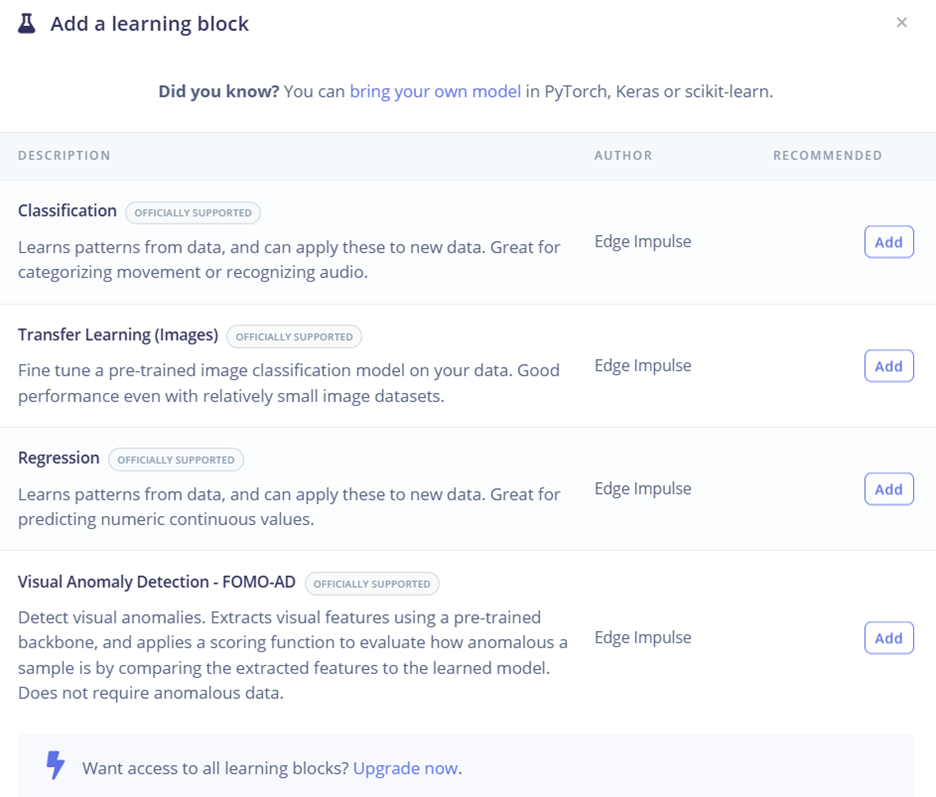
Hình 12. Add a learning block trong quá trình thiết kế Impulse
Output features: Kết quả đầu ra sẽ bao gồm 12 classes: 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, A, F.
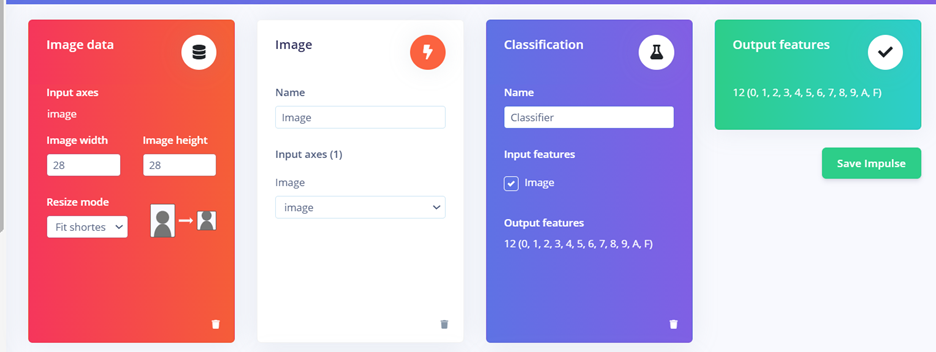
Hình 13. Output features của 12 lớp dữ liệu số/chữ
Bước 4. Chuyển về ảnh grayscale and save parameters để giảm độ phức tạp của mô hình mà vẫn giữ được đặc điểm hình dạng của chữ số/chữ cái.
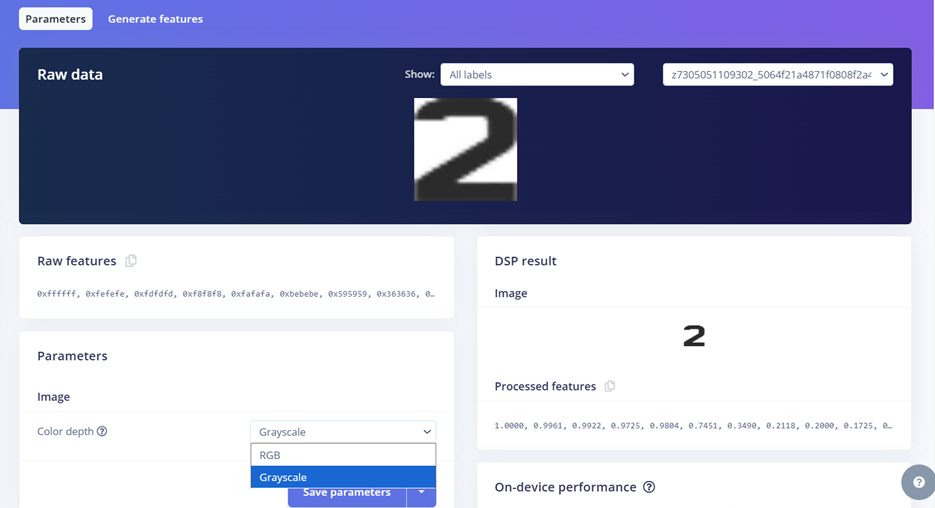
Hình 14. Chuyển về ảnh grayscale và Save parameters
Sau khi nhấn Generate features, hệ thống sẽ hiển thị một biểu đồ Feature explorer. Tại đây, các cụm dữ liệu cùng nhãn nên nằm gần nhau và tách biệt với các nhãn khác để đảm bảo mô hình dễ dàng phân loại.

Hình 15. Trích xuất đặc trưng của 12 lớp dữ liệu số/chữ
Bước 5. Tiếp theo là huấn luyện mô hình (bước Classifier). Tiếp theo là huấn luyện mô hình (bước Classifier). Sau khi chọn Classification trong khối Learning block để phân loại các đối tượng, Edge Impulse đã đề xuất 1 kiến trúc CNN mà phù hợp với dữ liệu đưa vào và phù hợp với output mà chúng ta mong muốn cho đề tài này.
Tuy nhiên trong quá trình train cũng có thể thay đổi thông số và thay đổi số lớp ở kiến trúc sao cho phù hợp với bài toán hoặc có thể trải nghiệm và tìm ra được model tối ưu nhất cho dự án. Nhưng trong dự án này, chúng tôi sử dụng các thông số mặc định.


Hình 16. Các thông số mặc định của 1 kiến trúc CNN do Edge Impulse đề xuất.
Sau khi quá trình huấn luyện hoàn tất, mô hình đạt được độ chính xác tối ưu 100% trên tập validation, như thể hiện trong hình bên dưới. Bên cạnh việc hiển thị các chỉ số đánh giá, Edge Impulse còn hỗ trợ thống kê chi tiết kết quả huấn luyện thông qua confusion matrix, giúp đánh giá mức độ chính xác của mô hình trên từng lớp dữ liệu. Ngoài ra, nền tảng này còn cho phép trực quan hóa các mẫu dữ liệu bị nhầm lẫn, giúp người dùng dễ dàng quan sát và phân tích nguyên nhân sai lệch, từ đó cải thiện chất lượng dữ liệu hoặc điều chỉnh mô hình nếu cần thiết.
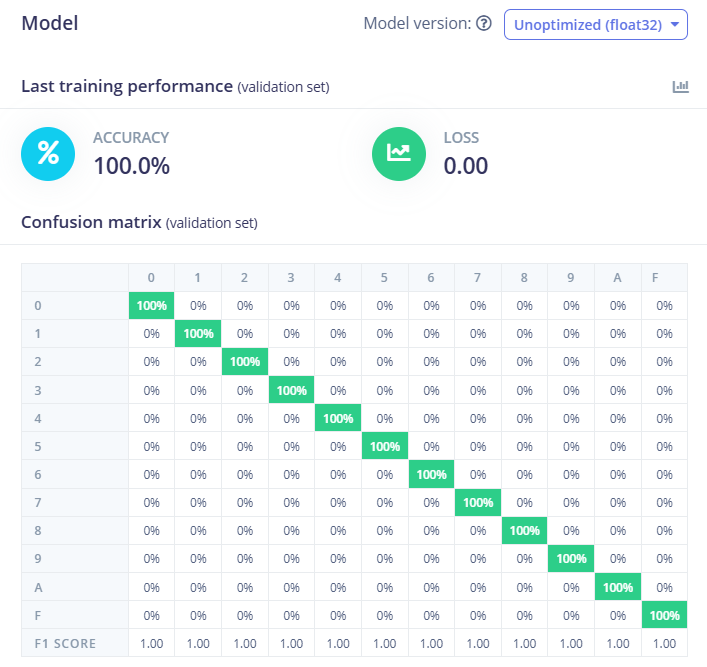
Hình 17. Độ chính xác của model AI
Bước 6. Chúng ta tiến hành kiểm tra tập testing bằng cách click vào Classify all để tiến hành testing model vừa training. Sử dụng tập test data mà mô hình chưa từng thấy để đánh giá độ chính xác thực tế. Kết quả cho thấy độ chính xác đạt 99.49%. Có thể nhìn thấy ở confusion matrix, có sự nhầm lẫn nhỏ giữa số 8 và số 6 (4.3%).
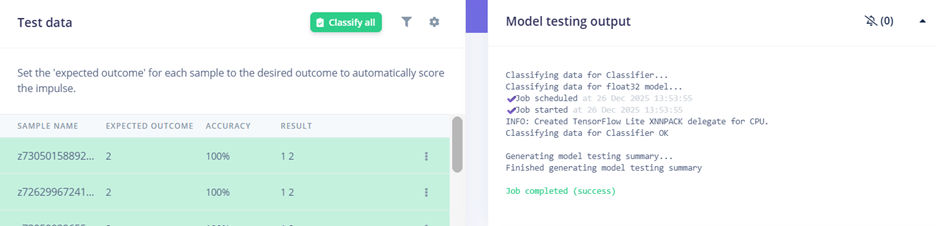
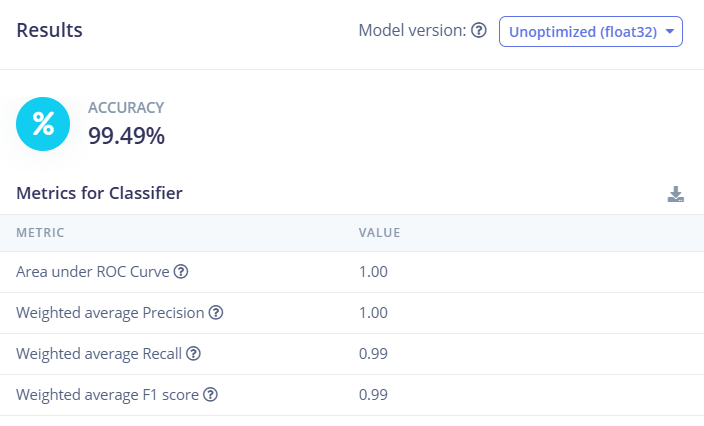
Hình 18. Sử dụng tập test data mà mô hình chưa từng thấy để đánh giá độ chính xác thực tế
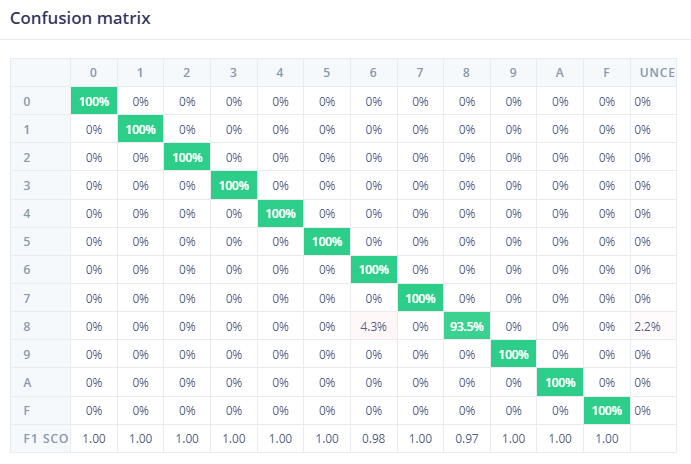
Hình 19. Confusion matrix
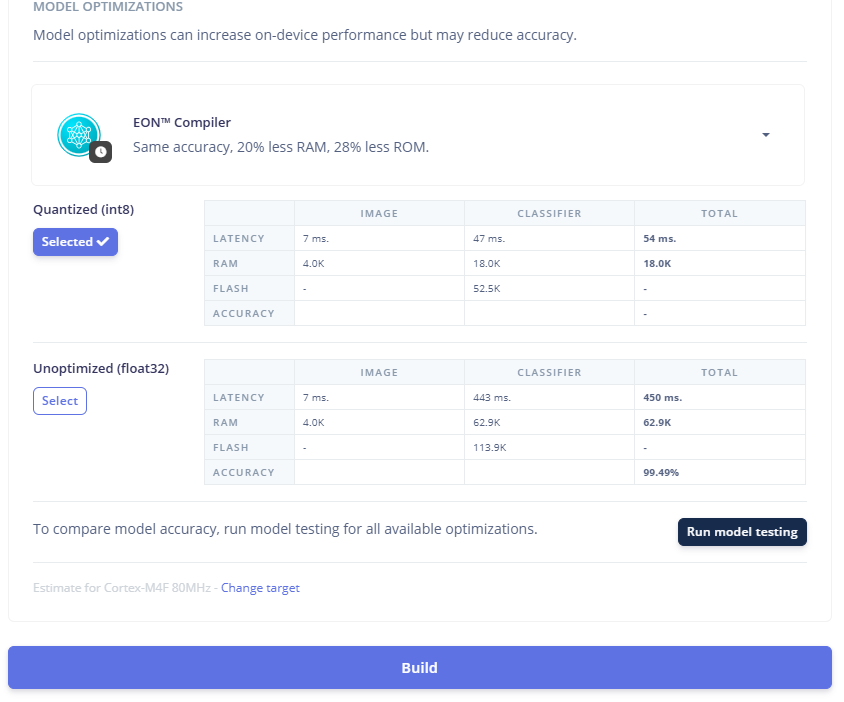
Edge Impulse còn hỗ trợ tối ưu hóa mô hình ở bước triển khai thông qua EON™ Compiler, giúp giảm khoảng 20% dung lượng RAM và 28% dung lượng ROM so với mô hình ban đầu. Sau khi huấn luyện, mô hình mặc định được tạo ở dạng float32, phù hợp cho các hệ thống có khả năng xử lý số thực tốt. Tuy nhiên, khi áp dụng kỹ thuật lượng tử hóa (Quantization) xuống INT8, độ trễ khi suy luận trên thiết bị giảm đáng kể, chỉ còn khoảng 54 ms, đồng thời mức sử dụng RAM và bộ nhớ Flash cũng giảm đi rõ rệt. Điều này đặc biệt hữu ích khi triển khai mô hình trên các vi xử lý hoặc vi điều khiển có tài nguyên hạn chế. Trong trường hợp các hệ thống nhúng có cấu hình cao hơn, người dùng vẫn có thể lựa chọn mô hình float32 để đảm bảo độ chính xác tối đa. Cần lưu ý rằng việc lượng tử hóa có thể ảnh hưởng nhẹ đến độ chính xác của mô hình, tuy nhiên trong project này, độ chính xác vẫn được giữ nguyên, cho thấy hiệu quả của quá trình tối ưu hóa.
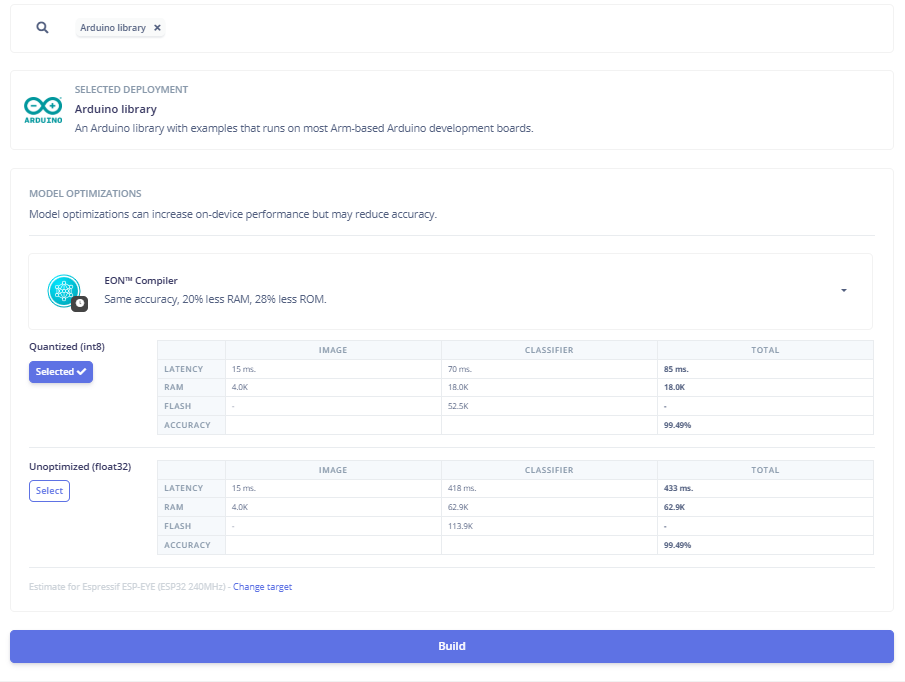
Hình 20. Tối ưu hóa model AI bằng phương pháp Quantized (int8)
2.3. Xuất model dưới dạng thư viện Arduino
Ở bước Deployment, Edge Impulse cho phép xuất mô hình dưới dạng Arduino library (tùy chọn mặc định), giúp mô hình có thể chạy trực tiếp trên thiết bị nhúng mà không cần kết nối Internet. Ngoài Arduino, người dùng cũng có thể lựa chọn các hình thức triển khai khác bằng cách tìm kiếm trong mục Search deployment options, tùy theo nền tảng phần cứng đang sử dụng.
Edge Impulse hỗ trợ triển khai mô hình trên nhiều loại phần cứng khác nhau, chủ yếu thông qua các thư viện C/C++. Ví dụ, khi tải mô hình ở dạng C++ library, thư viện này có thể được tích hợp và chạy trên hầu hết các vi điều khiển hoặc hệ thống nhúng. Trong trường hợp phát triển trên Arduino, người dùng chọn tùy chọn Arduino library; nếu làm việc với STM32, có thể chọn gói triển khai dành riêng cho STM32. Ngoài ra, nền tảng còn hỗ trợ nhiều môi trường và phần cứng khác, giúp mô hình dễ dàng được triển khai linh hoạt trên các hệ thống nhúng với cấu hình và tài nguyên khác nhau.
Hình 21. Lựa chọn model để tải về máy tính
Cuối cùng, bấm Build để tải thư viện về máy tính.
Hình 22. Tải thư viện về máy tính
3. Giải pháp thuật toán ở ESP32 CAM
3.1. Import model vào môi trường Adruino IDE
Trên thanh công cụ của phần Adruino IDE, vào Sketch -> Include Libray -> Add .ZIP Libray và sao đó chọn file model .ZIP đã được tải xuống từ Edge Impulse
Sau đó chỉ cần include tên thư viện chính là tên của thư mục vào chương trình code là có thể dùng được model:
|
1 |
#include <finalProject_inferencing.h> |
Hình 22. Thêm file model .ZIP vào dự án Arduino
Hình 23. Tên thư mục chứa model dùng để include
3.2. Chụp ảnh bằng ESP32 cam với thư viện esp32cam.h

Hình 24. ESP32 CAM
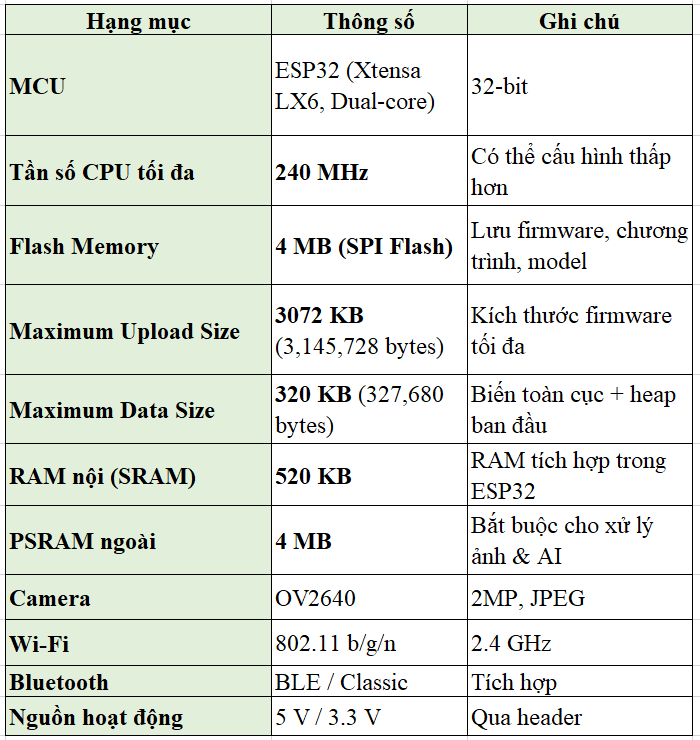
Bảng 1. Bảng thể hiện các thông số của ESP32 CAM
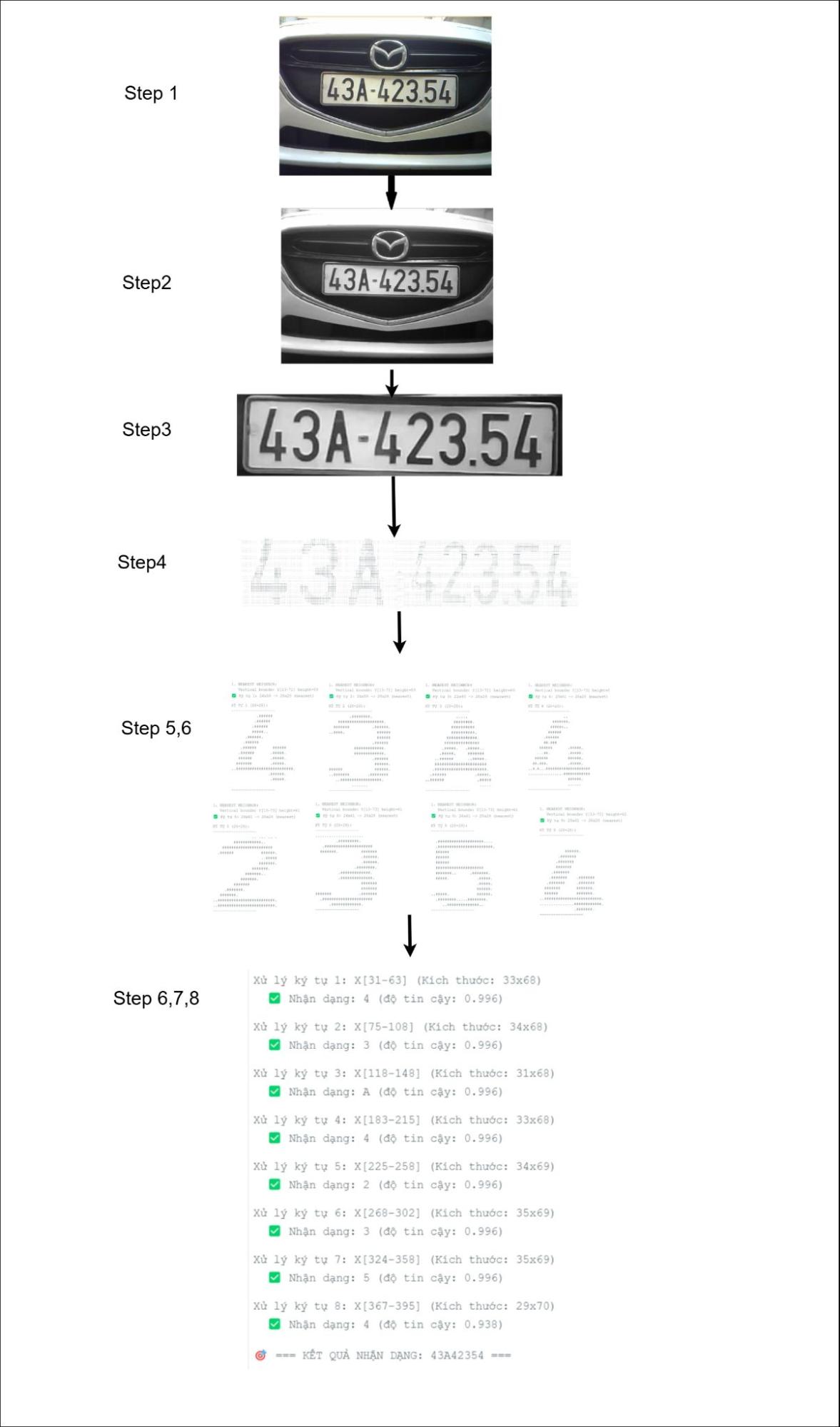
Hình 25. Sơ đồ minh họa các bước xử lý trên ESP32 CAM
3.2.1. Cấu hình cho ESP32 cam
Vì ESP cam lấy dữ camera về thông qua DMA, nên chúng ta sẽ dùng cơ chế DMA double buffering để giúp tránh mất mát dữ liệu và phù hợp với bài toán realtime hơn.
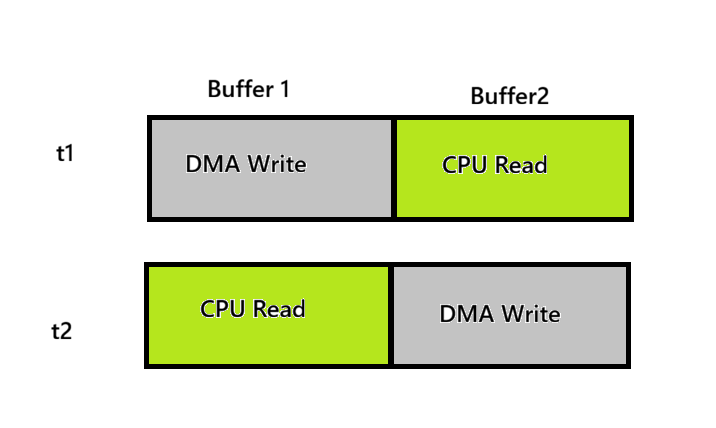
Hình 26. DMA double buffering
Ta sẽ cấu hình để tạo 2 buffer để cho DMA ghi luân phiên. Tức là trong 1 thời điểm thì DMA sẽ ghi vào 1 buffer và CPU sẽ đọc và xử lý buffer còn lại.
Chú ý: Nhiều model camera sẽ bị flip dọc, và ta muốn chụp chữ nên phải phản chiếu ngược qua gương để đọc nên sẽ cấu hình thêm cho sensor cam:
|
1 2 3 4 5 |
sensor_t *s = esp_camera_sensor_get(); if (s) { s->set_vflip(s, 1); s->set_hmirror(s, 1); } |
3.2.2. Thực hiện lấy buffer ảnh
|
1 |
camera_fb_t *fb = esp_camera_fb_get(); |
Gọi hàm esp_camera_fb_get()được hỗ trợ bởi thử viện esp32cam.h để lấy dữ liệu ảnh từ buffer để CPU xử lý.

Hình 27. Ảnh chụp từ ESP32CAM
3.2.3. Sử dụng thư viện để chuyển ảnh JPEG về gray scale để tiện cho xử lý

Hình 28. Ảnh sau khi chuyển về gray scale
3.2.3.1. Chuyển đổi từ JPEG sang RBG
Sử dụng hàm fmt2rgb888 để chuyển ảnh nén JPEG sang dùng dạng biểu diễn 1 pixel thành 3 pixle màu cơ bản.
|
1 |
bool converted = fmt2rgb888(jpeg_data, jpeg_len, PIXFORMAT_JPEG, rgb); |
Chú ý rằng hàm trên khi mã hóa bị sai thứ tự của pixel màu xanh và màu đỏ tức sau khi giải mã là brg. Nên ta cần 1 hàm đảo thứ tự pixel màu lại.
|
1 2 3 4 5 6 7 |
void bgr2rgb(uint8_t *buf, size_t pixels) { for (size_t i = 0; i < pixels; i++) { uint8_t tmp = buf[3 * i]; buf[3 * i] = buf[3 * i + 2]; buf[3 * i + 2] = tmp; } } |
3.2.3.2. Chuyển đổi từ RBG sang Gray scale bằng thuật toán Luminance Method 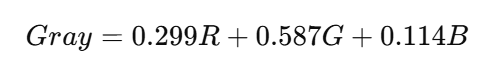
|
1 2 3 4 5 6 |
uint8_t *gray = (uint8_t*) malloc(pixels); if (!gray) { free(rgb); return; } for (size_t i = 0; i < pixels; i++) { uint8_t r = rgb[i * 3], g = rgb[i * 3 + 1], b = rgb[i * 3 + 2]; gray[i] = (uint8_t)((r * 30 + g * 59 + b * 11) / 100); } |
3.2.4. Tìm vùng biển số và cắt vùng biển số.

Hình 28. Biển số sau khi được tìm thấy và cắt ra
- Thuật toán trước hết kiểm tra tính hợp lệ và kích thước của ảnh đầu vào; nếu ảnh không đạt yêu cầu, một vùng giả định gần trung tâm ảnh được chọn dựa trên giả thiết biển số thường nằm ở vị trí này.
- Tiếp theo, ảnh được chuẩn hóa độ sáng và tăng tương phản bằng cách phân tích dải mức xám thực tế và kéo giãn dải động, nhằm giảm ảnh hưởng của điều kiện chiếu sáng và làm nổi bật biển số so với nền.
- Sau khi tiền xử lý, thuật toán phát hiện biên với trọng tâm là các biên dọc, vì các ký tự trên biển số chứa nhiều nét thẳng đứng đặc trưng.
- Các phép toán hình thái học được áp dụng để nối liền các biên bị đứt đoạn, tạo ra các cấu trúc liên tục thuận lợi cho việc xác định vùng.
- Dựa trên đặc điểm nền sáng, hình dạng chữ nhật và tỷ lệ hình học của biển số, các vùng sáng liên thông được trích xuất, phân tích và lọc bỏ những vùng không phù hợp.
- Vùng ứng viên tốt nhất được lựa chọn dựa trên mức độ tương đồng hình học; nếu không có vùng đạt yêu cầu, thuật toán chuyển sang phương án dự phòng dựa trên mật độ biên.
- Cuối cùng, vùng biển số được cắt ra theo kết quả xử lý để dùng cho bước tiếp theo.
3.2.5. Xử lý để loại bỏ viền đen và vùng thừa

Hình 29. Biển số sau khi loại bỏ viền và các phần thừa
- Xác định điểm trung tâm của biển số để và thực hiện quy định 2 đoạn ngang có độ dài từ tâm đến cách cạnh 30 pixel ( để hạn chế tác động của pixel nhiễu.
- Để lọc viền đen cho 2 cạnh trên và dưới, ta thực hiện quét pixel theo phương y, từ tâm lên cạnh trên và từ tâm xuống cạnh dưới. Ta sẽ tiến hành kiểm tra giá trị của pixel trong đoạn thẳng bên trái và bên phải 1 cách độc lập. Đường quét ngang sẽ đi dịch về phía biên cho đến khi gặp đường ngang có số pixel trắng là 100 % ( vùng viền trắng) thì có tiến hành quét thêm 10 hàng pixel nữa, nếu hết 10 hàng đó mà đều là pixel trắng thì chọn điểm cắt viền là ở đó, nếu không thì sẽ cắt ở hàng có 100% pixel trắng gần nhất. Và ta sẽ so sánh điểm cắt của đường bên phải và đường bên trái, nếu đường nào gần tâm hơn thì sẽ chọn điểm cắt từ đó để phòng biển số bị nghiêng.
- Để lọc viền đen trái phải, ta thực hiện quét pixel từ cạnh vào trong, nếu gặp vùng đen có độ dài 3 pixel liên tiếp thì thực hiện cắt từ mốc đó.
3.2.6. Tìm các kí tự và cắt chúng ra thành các phần riêng biệt.
Thuật toán khai thác đặc điểm hình ảnh của biển số, trong đó các ký tự tạo ra vùng có mật độ điểm ảnh đen cao, trong khi giữa hai ký tự tồn tại các dải cột có rất ít hoặc không có điểm ảnh đen (Tức một dãy pixel đen nằm giữ 2 dãy pixel trắng).
Do các ký tự được sắp xếp theo phương ngang, sự phân bố điểm ảnh đen theo trục X mang đầy đủ thông tin để xác định ranh giới phân tách ký tự.
Sau khi tìm được vị trí các khoảng pixel nằm giữa 2 khoảng pixel trắng thì ta tiếng hành cắt các kí tự theo size thực của biển số ra.
3.2.6.1. Các bước thực hiện
Bước 1 – Chiếu ảnh từ không gian 2D sang biểu diễn 1D theo trục X
![]()
Hình 30. Ví dụ về cách xác định cột pixel đen cho mảng 2 chiều
Bước 2 – Phát hiện các khe trắng tương đối
Bước 3 – Phân đoạn ký tự theo các khe trắng
Bước 4 – Lọc ký tự theo kích thước hình học
3.2.7. Resize mỗi kí tự về kích thước ảnh của model
3.2.7.1. Mục đích của bước resize
Sau khi một vùng ký tự hợp lệ đã được xác định, ký tự này cần được chuẩn hóa về kích thước cố định 28×28 pixel nhằm đảm bảo tính đồng nhất của dữ liệu đầu vào cho bộ nhận dạng. Do kích thước thực tế của các ký tự có thể khác nhau, cần thực hiện phép ánh xạ từ ảnh gốc sang ảnh đích có kích thước chuẩn.
3.2.7.2. Nguyên lý ánh xạ của thuật toán Nearest Neighbor
Thuật toán Nearest Neighbor dựa trên nguyên lý:
Mỗi điểm ảnh trong ảnh đích được gán giá trị của điểm ảnh gần nhất tương ứng trong ảnh nguồn.
Phương pháp này không nội suy giá trị cường độ, mà chỉ sao chép trực tiếp giá trị pixel từ ảnh nguồn, do đó phù hợp với ảnh ký tự nhị phân hoặc ảnh có độ tương phản cao.
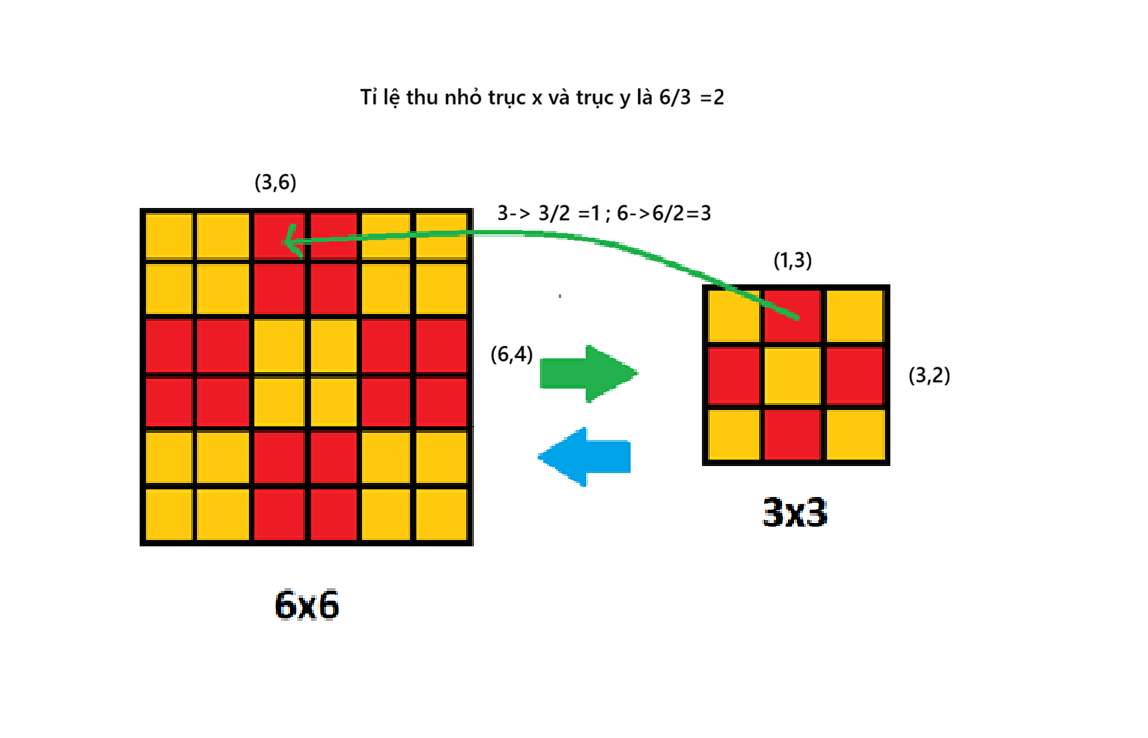
Hình 31. Ví dụ về cách ánh xạ bằng thuật toán Nearest

Hình 32. Kết quả resize trên ESP32 cam
3.2.8. Normal hóa ảnh để tạo features đúng với yêu cầu của model
Dựa vào example của thư viện xuất từ Edge Impulse, ta phải chuẩn hóa dữ liệu để có features tương thích với model trước khi đưa vào dự đoán. Mô hình được trainning ở dạng graysacle nên sẽ áp dụng cách chuyển về graysacle mà công cụ dùng. Edge Impulse không dùng cách chia gray pixel cho 255 để chuẩn hóa bằng công thức sau:
out_ptr[out_ptr_ix] = (float)((gray << 16) + (gray << 8) + gray);
Còn đây là hàm thực hiện chuẩn hóa :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
static uint8_t* current_image_data = nullptr; static int get_image_data(size_t offset, size_t length, float *out_ptr) { if (current_image_data == nullptr) { return -1; } size_t pixel_ix = offset; size_t pixels_left = length; size_t out_ptr_ix = 0; while (pixels_left != 0) { uint8_t gray = current_image_data[pixel_ix]; out_ptr[out_ptr_ix] = (float)((gray << 16) + (gray << 8) + gray); out_ptr_ix++; pixel_ix++; pixels_left--; } return 0; } |
3.2.9. Load vectors input vào model và xuất kết quả dự đoán.
Sau bước resize, ta có 1 mảng lưu các kí tự đã resize ta tiến hành đưa lần lược chuẩn hóa từng phần tử kí tự này và đưa vào model để dự đoán. Và ta sẽ lưu kết quả dự đoán vào 1 mảng kí tự, và sao đó ghép chuỗi chúng lại để có 1 biển số hoàn chỉnh.
EI_IMPULSE_ERROR res = run_classifier(&signal, &ei_result, debug_nn);
Thử viện hỗ trợ hàm trên để đưa dữ liệu model vào thông qua parameter signal và kết quả dự đoán được trả về ở ei_result.
Hàm thực hiện ở đây:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
PredictionResult predictCharacterFromImage(uint8_t* image_data, int img_width, int img_height, const String& methodName) { PredictionResult result; result.success = false; result.confidence = 0.0f; result.predictedChar = '?'; result.labelIndex = 0; result.methodName = methodName; if (EI_CLASSIFIER_RAW_SAMPLE_COUNT != img_width * img_height) { return result; } if (image_data == nullptr) { return result; } current_image_data = image_data; ei::signal_t signal; signal.total_length = EI_CLASSIFIER_RAW_SAMPLE_COUNT; signal.get_data = &get_image_data; ei_impulse_result_t ei_result = { 0 }; EI_IMPULSE_ERROR res = run_classifier(&signal, &ei_result, debug_nn); if (res != EI_IMPULSE_OK) { current_image_data = nullptr; return result; } float max_prob = 0.0f; uint16_t max_idx = 0; for (uint16_t i = 0; i < EI_CLASSIFIER_LABEL_COUNT; i++) { float prob = ei_result.classification[i].value; if (prob > max_prob) { max_prob = prob; max_idx = i; } } const char* predicted_label = ei_classifier_inferencing_categories[max_idx]; if (strlen(predicted_label) > 0) { result.predictedChar = predicted_label[0]; } else { result.predictedChar = '?'; } result.confidence = max_prob; result.labelIndex = max_idx; result.success = true; current_image_data = nullptr; return result; } PredictionResult predictResizedCharacter(const ResizedCharacter& character) { return predictCharacterFromImage((uint8_t*)character.pixels, 28, 28, character.methodName); } |

Hình 33. Kết quả sau khi dự đoán
4. Kết luận:
Nhìn chung, Quá trình huấn luyện mô hình nhận diện ký tự biển số xe trên Edge Impulse được thực hiện đầy đủ và hiệu quả, từ khâu chuẩn bị dữ liệu, thiết kế Impulse đến huấn luyện và đánh giá mô hình. Nhờ dữ liệu được tiền xử lý và chuẩn hóa tốt, mô hình đạt độ chính xác cao với 100% trên tập validation và 99.49% trên tập testing. Việc sử dụng các công cụ đánh giá như confusion matrix giúp kiểm tra và phân tích kết quả một cách trực quan. Bên cạnh đó, mô hình sau khi được tối ưu bằng EON™ Compiler và lượng tử hóa INT8 vẫn giữ nguyên độ chính xác, đồng thời giảm đáng kể dung lượng bộ nhớ và độ trễ, phù hợp để triển khai trên các thiết bị nhúng có tài nguyên hạn chế.
Thiết bị giám sát bãi đỗ xe hoạt động ổn định và đáng tin cậy, đáp ứng tốt yêu cầu về tốc độ xử lý, khả năng thời gian thực và độ chính xác nhận dạng ký tự trong điều kiện chiếu sáng tiêu chuẩn. Kết hợp giữa ESP32-CAM và các thuật toán xử lý biển số dựa trên DSP, hệ thống có thể phát hiện biển số, tách ký tự và xác thực phương tiện với độ nhất quán cao.
Tuy nhiên, hiệu năng có thể suy giảm trong môi trường thực tế khi biển số bị chói sáng, che khuất, phản xạ, chụp ở góc nghiêng hoặc có hình dạng không chuẩn. Do đó, hệ thống cần được cải thiện ở khâu tiền xử lý, điều khiển phơi sáng thích nghi, bố trí camera hợp lý hơn, hoặc tích hợp mô hình học sâu mạnh hơn để nâng cao độ chính xác trong nhiều điều kiện khác nhau.
Chúc các bạn thành công!
Võ Văn Bưu, Lương Như Quỳnh