

AI Edge là một hướng nghiên cứu tìm năng với rất nhiều ứng dụng trong các lĩnh vực khác nhau. Tuy nhiên, việc thiết kế và nhúng mô hình trí tuệ nhân tạo lên các thiết bị edge như các vi điều khiển là một quá trình phức tạp với những người mới bắt đầu. Quá trình này phuộc thuộc sâu vào phần cứng, và các thư viện, phần mềm hỗ trợ và yêu cầu các kiến thức cả về Trí tuệ nhân tạo, xử lý tín hiệu số và các kiến thức về hệ thống nhúng như vi điều khiển, vi xử lý.
Với xu thế Edge AI, gần đây các hãng vi điều khiển cũng như các bên phát triển sản phẩm, ứng dụng và dịch vụ cũng nhanh chóng tham gia và cung cấp cho khách hàng các công cụ, thư viện hỗ trợ hoặc thậm chí những dòng vi điều khiển, vi xử lý chuyên cho Edge AI. Hãng STMicroelectronics cũng vậy, họ có những giải pháp giúp triển khai AI trên các thiết bị vi điều khiển STM32. Các bạn có thể xem qua 2 bài viết có liên quan mà TAPIT đã chia sẻ trước đây:
- Giải pháp của ST giúp triển khai mạng Nơ-ron nhân tạo trên STM32
- X-CUBE-AI: Gói phần mềm AI cho STM32CubeMX
Trong bài viết này, mình sẽ cung cấp các hướng dẫn để các bạn có thể triển khai một mô hình trí tuệ nhân tạo lên thiết bị vi điều khiển STM32 phục vụ cho các nghiên cứu, thử nghiệm Edge AI một nhanh chóng. Bài toán mình thực hiện là nhận dạng (phân loại) âm thanh trên vi điều khiển STM32.
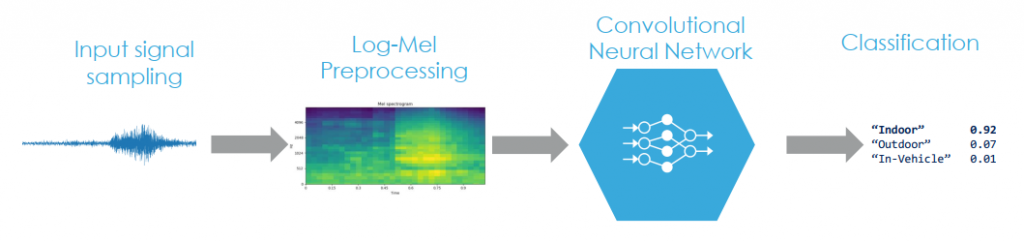

Hình 1.Quy trình phân loại âm thanh.
Mình sẽ hướng dẫn và phân tích quá trình thực hiện một cách tóm tắt ngắn gọn theo 5 bước như sau:
Bước 1: Thu thập dữ liệu
Bước đầu tiên đó là thu thập dữ liệu để xây dựng tập cơ sở dữ liệu. Tùy thuộc vào loại âm thanh mà bạn muốn nhận dạng thì chúng ta sẽ tiến hành thu thập dữ liệu của loại âm thanh đó. Chẳng hạng với ứng dụng điều khiển bật tắt một thiết bị nào đó, ta tiến hành thu thập dữ liệu âm thanh các từ khóa “on”/ “off” với số lượng đủ lớn và đủ độ đa dạng để làm tập dữ liệu huấn luyện mô hình.
Bước 2. Hiệu chỉnh, gắn nhãn dữ liệu và lựa chọn AI framework
- Hiệu chỉnh, gán nhãn dữ liệu
- Khi có được dữ liệu thô, ta tiếp tục tiến hành cắt dữ liệu ra từng đoạn âm thanh có kích thước cố định với định dạng .wav.
- Trích xuất đặc trưng Log-Mel Spectrogram. Ngày nay, trong các hệ thống nhận dạng hay xử lý âm thanh, có hai cách trích xuất đặc trưng phổ biến nhất đó chính là Log-Mel Spectrogram và MFCC. Trong đó MFCC là cách trích đặc trưng được biến đổi thêm một vài phép toán học từ Log-Mel Spectrogram. Tốc độ xử lý của thiết bị vi điều khiển sẽ có giới hạn, vậy nên ở đây ta sử dụng Log-Mel Spectrogram để giảm thiểu thời gian xử lý của vi điểu khiển, giúp tăng khả năng đáp ứng của hệ thống.
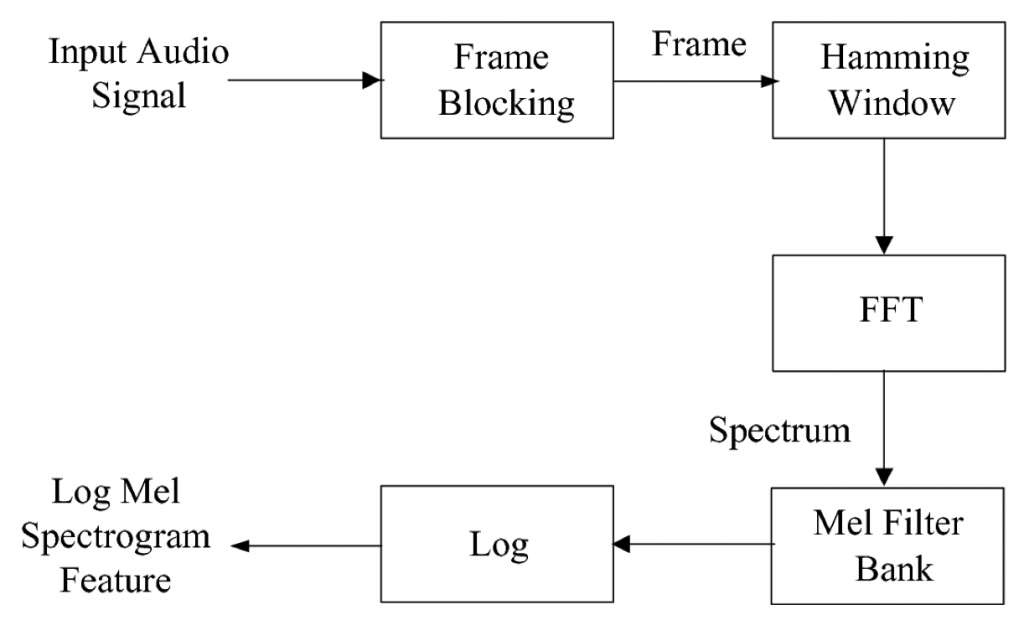
Hình 2. Quá trình trích xuất đặc trưng - Sau khi xử lý xong, các file được gán nhãn với đúng loại âm thanh của nó và lưu theo cấu trúc file .csv để tạo thành một dataframe phục vụ cho quá huấn luyện mô hình sau đó.

- Lựa chọn mô hình
- Với bài toán phân loại âm thanh thuộc nhánh xử lý ngôn ngữ tự nhiên (Natural Language Processing – NLP) thì Recurrent Neural Network (RNN) là một mô hình thường được lựa chọn. Tuy nhiên, với tính chất của dữ liệu và bài toán, chúng ta có thể sử dụng mô hình Convolutional Neural Network (CNN) để thực hiện bài toán này, giúp giảm thiểu thời gian, chi phí tính toán mà vẫn đạt được kết quả như mong muốn.
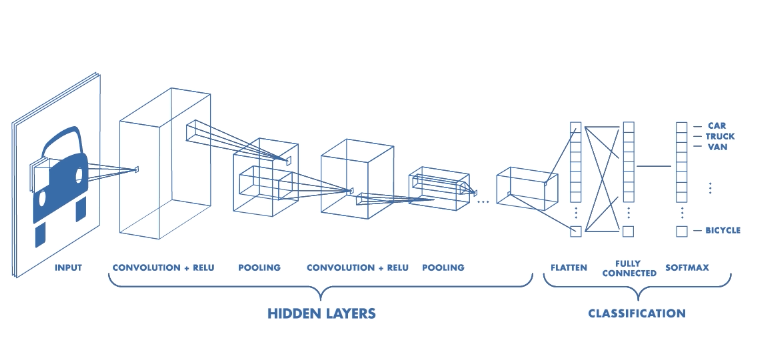

Hình 3. Cấu trúc cơ bản của mô hình Convolutional Neural Network (CNN)
Bước 3: Huấn luận mô hình trí tuệ nhân tạo
– Sau khi đã có được tập dữ liệu chuẩn ta sẽ tiến hành huấn luyện nó với mô hình đã lựa chọn, kết quả có được sau quá trình huấn luyện sẽ là một mô hình có thể nhận dạng được những dữ liệu âm thanh hoàn toàn mới được thu thập thông qua cảm biến từ môi trường.
- Đánh giá, kiểm thử và tối ưu
- Để đánh giá được mô hình, chúng ta sẽ dựa vào các thông số đánh giá như Confusion matrix, Precision, Recall, F1 score,… sau đó tiếp tục sử dụng các phương pháp tối ưu để có được một mô hình với độ chính xác mong muốn.
- Khi đã huấn luyện mô hình thành công, các bạn sẽ có một mô hình bao gồm trọng số weight, bias và thông số cấu hình model được lưu dưới dạng file .h5. Đây sẽ là mô hình cuối cùng được triển khai xuống vi điều khiển.
- Một mô hình do mình đào tạo được, các bạn có thể tham khảo: “mode_key.h5” tại đây. Model bao gồm 8 keyword “bật/tắt”: đèn, tivi, máy chiếu, điều hòa; 1 keyword “trợ lý” và 1 background noise
Bước 4. Chuyển đổi mô hình trí tuệ nhân tạo thành mã được tối ưu hóa cho vi điều khiển STM32
Sau khi đã xây dựng được một mô hình trí tuệ nhân tạo, công việc tiếp theo của bạn là triển khai mô hình đó xuống vi điều khiển. STM32Cube AI là một công cụ do hãng ST cung cấp giúp cho việc triển khai mô hình trí tuệ nhân tạo của các bạn lên thiết bị vi điều khiển STM32 sẽ trở nên cực kì dễ dàng.


Hình 4. Công cụ STM32Cube AI.
Tải công cụ STM32Cube AI tại đây.
Các bước triển khai:
1. Tạo project mới, lựa chọn vi điều khiển có hỗ trợ công cụ Cube AI, sau đó đặt tên cho project:
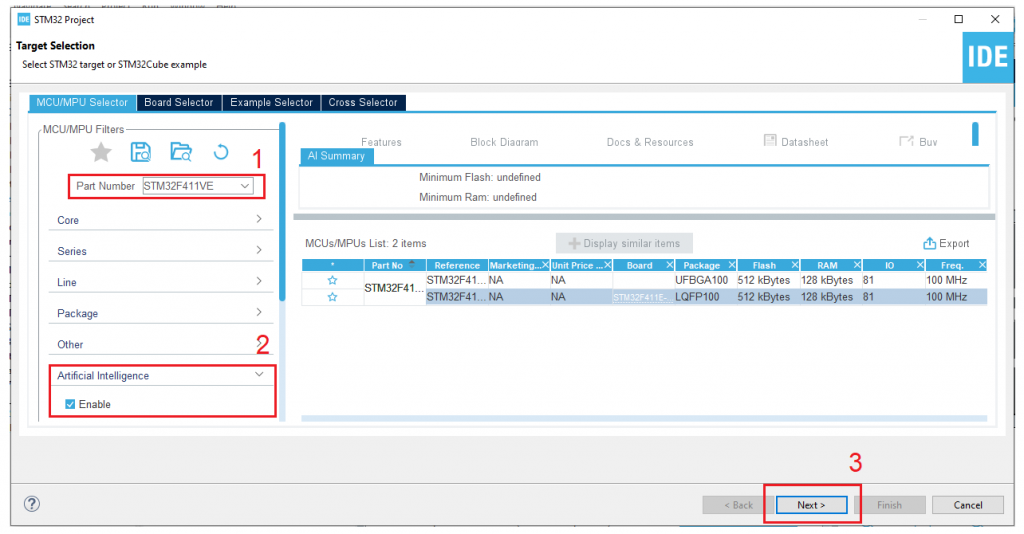

2. Kích hoạt công cụ Cube AI tại Software Packs:
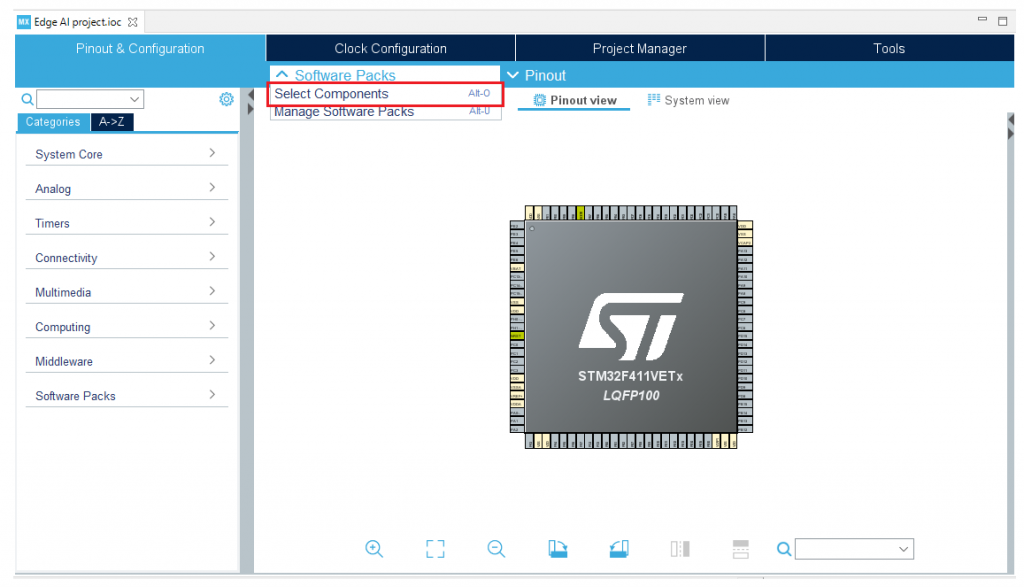

3. Tiến hành lựa chọn Version và kích hoạt Application:
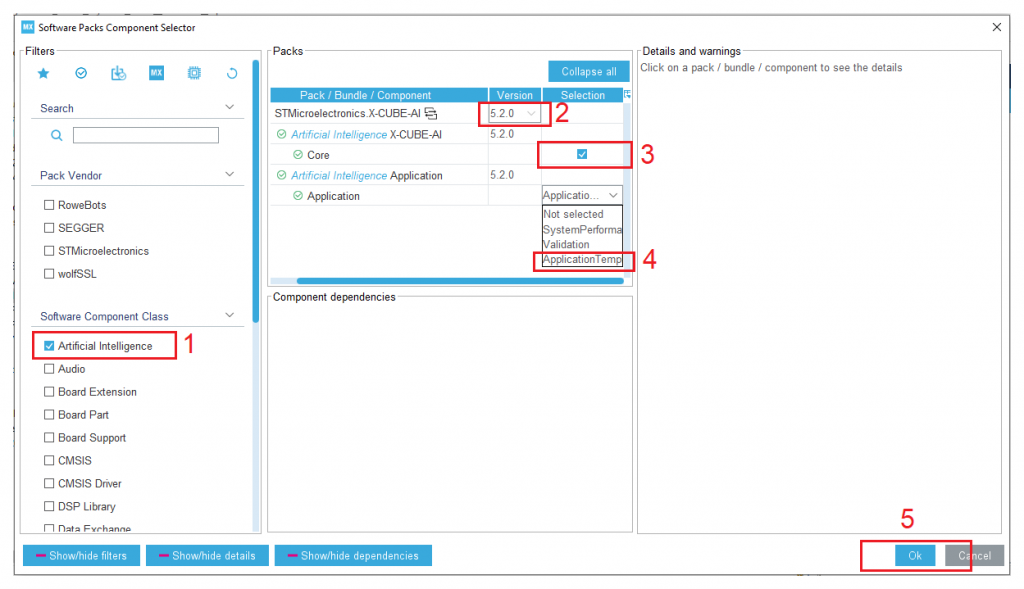

4. Tải mô hình đã huấn luyện được lên Cube AI và tiến hành Analyze tại Software Packs:
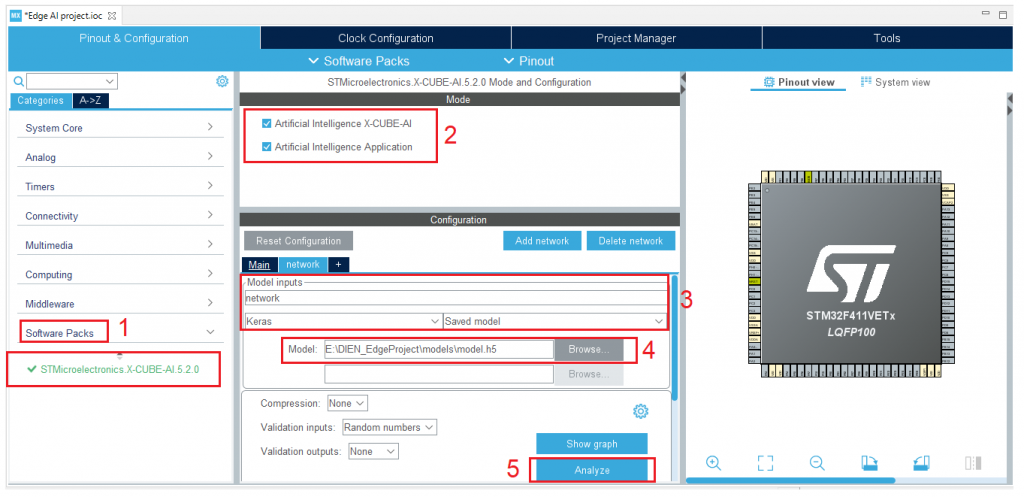

5. Sau khi quá trình Analyze hoàn thành cũng đồng nghĩa với việc chúng ta đã triển khai mô hình thành công. Bước cuối cùng là tiến hành thu thập dữ liệu thực tế từ sensor và thực hiện quá trình nhận dạng cục bộ bằng các thư viện có được nhờ công cụ X-Cube-AI:
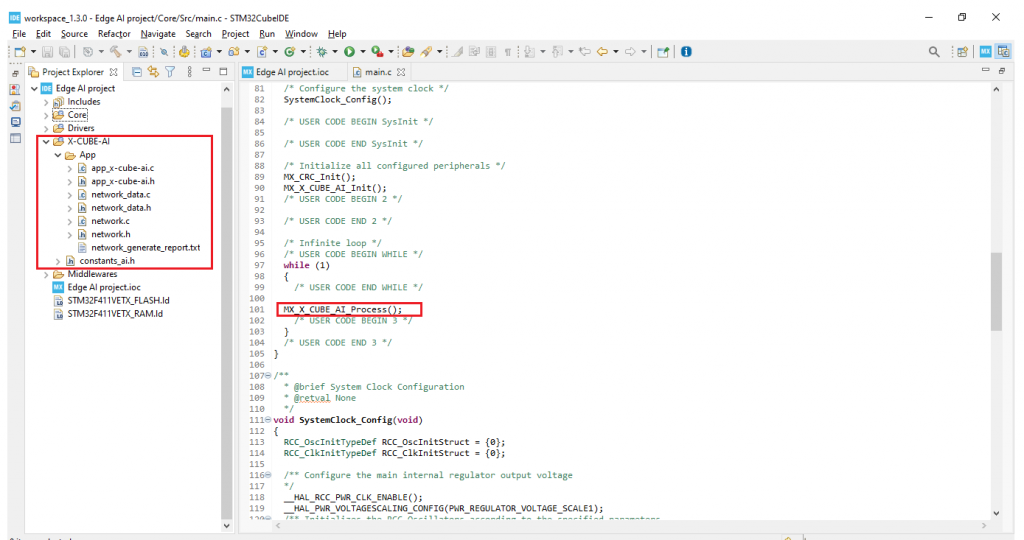

Bước 5. Xử lý dữ liệu mới trên vi điều khiển bằng mô hình trí tuệ nhân tạo đã nhúng
- Lấy dữ liệu âm thanh từ Microphone
Sau khi triển khai thành công mô hình đã đào tạo được xuống vi điều khiển, ta tiến hành thu thập dữ liệu âm thanh từ cảm biến (ở đây sẽ là từ microphone) để tiến hành nhận dạng một cách trực tiếp.
1. Cấu hình ngoại vi ADC của vi điều khiển STM32 để ngoại vi ADC của STM32 sẽ giao tiếp với microphone này để lấy dữ liệu âm thanh với tần số lấy mẫu là 16KHz (giống với tần số lấy mẫu âm thanh lúc huấn luyện mô hình):
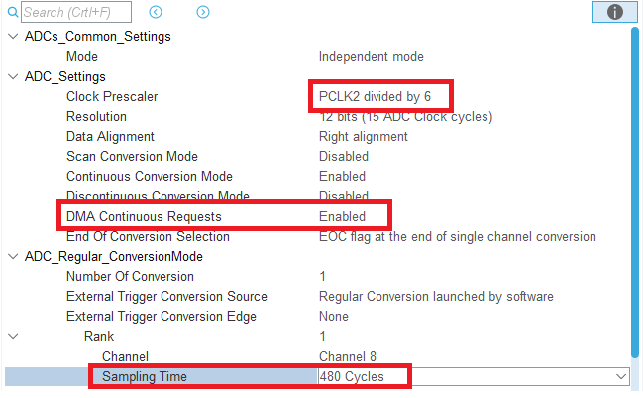

Cấu hình ADC trên vi điều khiển STM32
2. Cấu hình DMA ở chế độ Circular để chuyển dữ liệu từ ngoại vi ADC liên tục vào bộ nhớ.
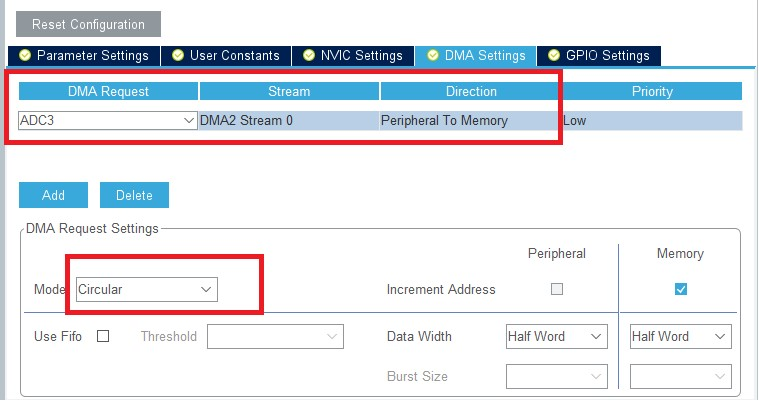

Cấu hình DMA trên vi điều khiển STM32
3. Thiết kế bộ đệm vòng nhận dữ liệu ADC liên tục
ADC sẽ hoạt động kết hợp với DMA ở chế độ Circular nên ta xét đến Bộ đệm vòng hay còn được gọi là Ring buffer. Ring buffer là một bộ đệm có kích thước cố định, có thể đọc có thể đọc dữ liệu mà không làm mất di dữ liệu cũ trước đó kể cả khi bộ nhớ đầy thì vẫn có thể quay lại từ đầu và ghi vòng lên dữ liệu cũ giúp ta không làm mất dữ liệu và luôn có dữ liệu mới nhất. DMA sẽ chuyển dữ liệu từ ngoại vi ADC của vi điều khiển vào Bộ đệm vòng một cách liên tục.
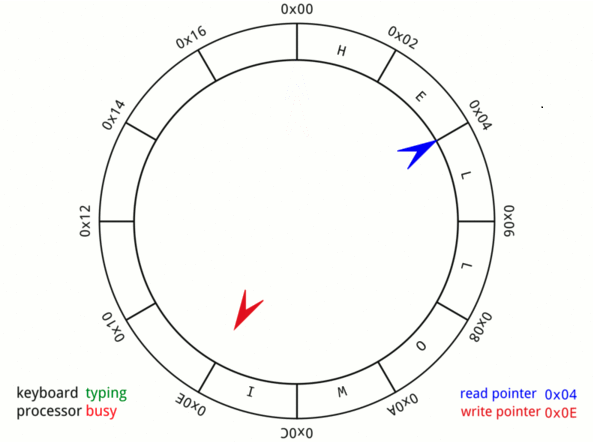

Bộ đệm vòng Ringbuffer
Muốn tìm vị trí của dữ liệu tiếp theo thì phải dựa vào giá trị của thanh ghi NDTR. Thanh ghi này là thanh ghi ngược chứa giá trị số phần tử còn lại của bộ đệm chưa được ghi dữ liệu, nên vị trí của dữ liệu tiếp theo được ghi sẽ bằng kích thước của bộ đệm trừ đi giá trị của thanh ghi NDTR.


Thanh ghi NDTR của vi điều khiển STM32.
[HỌC ONLINE TẠI TAPIT: LẬP TRÌNH VI ĐIỀU KHIỂN STM32, VI XỬ LÝ ARM CORTEX – M]
4. Trích đặc trưng Log-Mel Spectrogram trên vi điều khiển
Có một sự khác biệt ở đây đó là nếu trên máy tính tiến hành trích đặc trưng cho các file âm thanh đã được thu sẵn bằng ngôn ngữ Python, thư viện Librosa thì việc trích đặc trưng trên vi điều khiển sẽ tiến hành với âm thanh thực tế được lấy từ microphone và thực hiện bằng ngôn ngữ C cùng với thư viện CMSIS.
Một chú ý ở đây là các thông số trích đặc trưng trên máy tính và dưới vi điều khiển phải hoàn toàn giống nhau để có được sự động bộ dữ liệu, thì lúc đó mô hình thực thi mới có được độ chính xác.
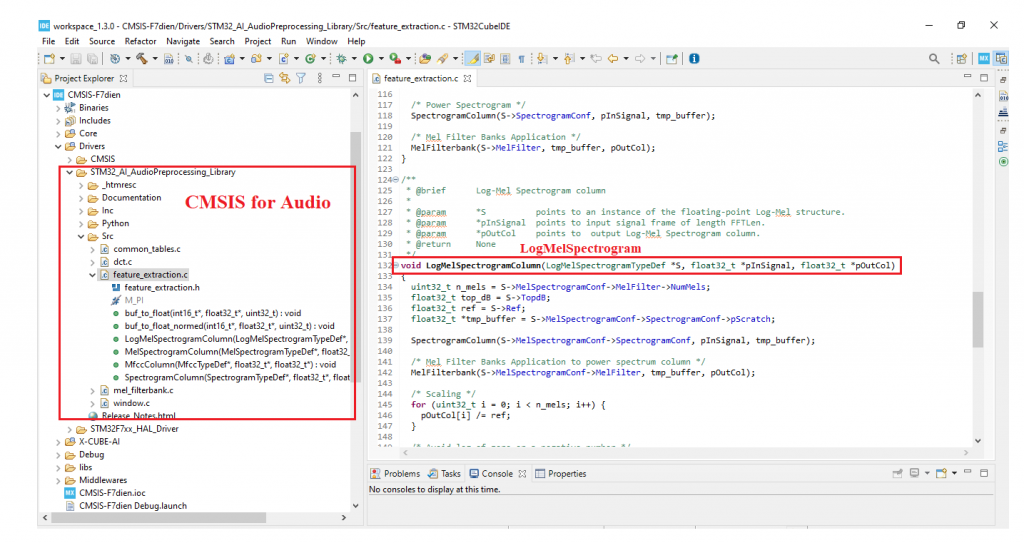

Thư viện CMSIS Audio cho vi điều khiển STM32
5. Thực thi mô hình trên vi điều khiển để nhận dạng âm thanh
Sau khi đã tiến hành trích đặc trưng thành công, cuối cùng ta tiến hành chạy hàm ai_run(aSpectrogram, data_out) với aSpectrogram là dữ liệu âm thanh thu từ microphone đã được trích đặc trưng dưới vi điều khiển, data_out sẽ là mảng xác suất nhận dạng của các từ khóa mà mô hình nhận dạng được.
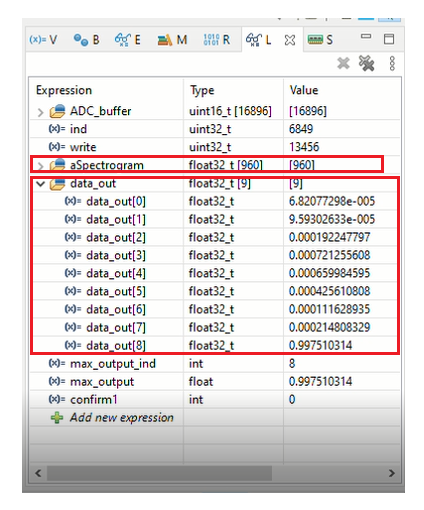

Giao diện debug kết quả
Từ kết quả này các bạn có thể kết hợp thêm màn hình LCD để hiển thị hoặc các module truyền thông mạng như WiFi, 3G/4G hoặc Ethernet để có thể đưa kết quả nhận dạng lên Cloud và đến ứng dụng người dùng.
Vậy với bài viết này, mình đã trình bày cho các bạn các bước cơ bản để xây dựng một mô hình trí tuệ nhân tạo, và sau đó triển khai nó lên thiết bị vi điều khiển STM32. Chúc các bạn thành công!
Nhóm AI R&D
Duy Dien, Thuong Nguyen