

Trong machine learning (học máy), classification (phân loại) đề cập đến việc predict (dự đoán) label (nhãn) của một đầu vào dữ liệu. Bài viết này sẽ đề cập đến các thông số đo lường, phương đánh giá mô hình phân loại được sử dụng phổ biến: accuracy, precision, recall, F-1 Score, ROC curve, và AUC. So sánh giữa 2 thông số đo lường mà mọi người dễ nhầm lẫn là precision và recall.
Trong bài viết này, có một số thuật ngữ được sử dụng như sau:
- Predicted (giá trị dự đoán): là kết quả dự đoán của mô hình
- Actual (giá trị thực): thu được bằng cách quan sát hoặc đo lường thực tế dữ liệu (luôn luôn đúng)
- Positive – P và Negative – N
- True Positive – TP: giá trị actual và predicted đều là positive
- False Positive – FP: giá trị actual là negative nhưng predicted là positive
- True Negative – TN: giá trị actual và predicted đều là negative
- True Positive – TP: giá trị predicted là negative nhưng actual là positive
1. Binary Classification (phân loại nhị phân)
Binary classification, giống như cái tên là giải quyết các bài toán phân loại chỉ có 2 nhãn. Nói chung, một câu hỏi có/không hoặc một thiết lập với kết quả 0-1 được mô hình hóa như một bài toán nhị phân. Ví dụ như bài toán xem một email có phải là spam hay không.
Với 2 nhãn, có thể nói về mẫu positive (tích cực) và mẫu negative (tiêu cực) sample. Trong trường hợp này, có thể nói email là spam (positive – tích cực) hoặc không spam (negative – tiêu cực).
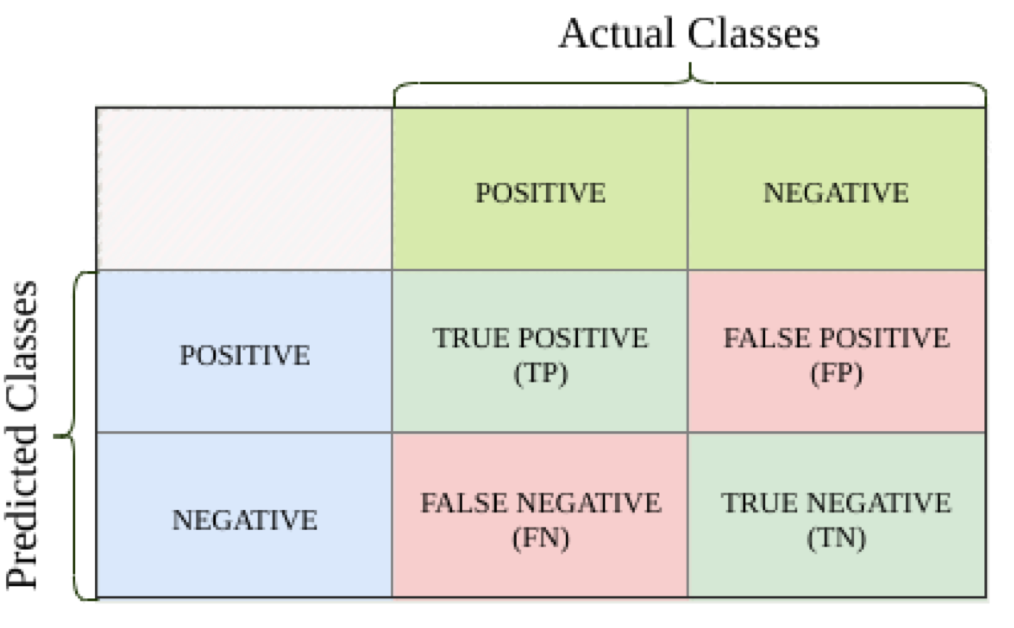

Đối với một sample nhất định, actual class có thể là postive và negative. Tương tụ với predicted class cũng được coi là postive và negative. Sử dụng confusion matrix (ma trận nhầm lẫn) để có thể dễ dàng hình dung kết quả của mô hình được trình bày ở hình trên. Trong đó:
- True Positive (TP): predict và actual đều là positive (mô hình phân loại đúng mẫu positive)
- False Positive (FP): actual là positive nhưng predict lại là negative (mô hình bị nhầm lẫn mẫu positive là negative)
- True Negative (TN): predict và actual đều là negative (mô hình phân loại đúng mẫu negative)
- False Negative (FN): actual là negative nhưng predict là positive (mô hình bị nhầm lẫn mẫu negative là positive)
Đường chéo của confusion matrix thể hiện các dự đoán chính xác. Rõ ràng mô hình càng tin cậy nếu phần lớn các dự đoán nằm ở đó.
FPs và FNs là phân loại sai. Trong một số trường hợp, FNs là nguy hiểm và không thể chấp nhận được. Ví dụ nếu bộ phân loại dự đoán có cháy trong nhà hay không thì FP là báo động giả, còn FN nghĩa là nhà đang cháy nhưng không báo động.
2. Các phương pháp đo lường đánh giá binary classification
Giả sử trường hợp phân loại nhị phân đơn giản như hình dưới. Các mẫu positive và negative actual được phân bố trên bề mặt hình chữ nhật. Tuy nhiên, mô hình phân loại lại coi như các mẫu bên trong hình tròn là positive còn bên ngoài là negative.
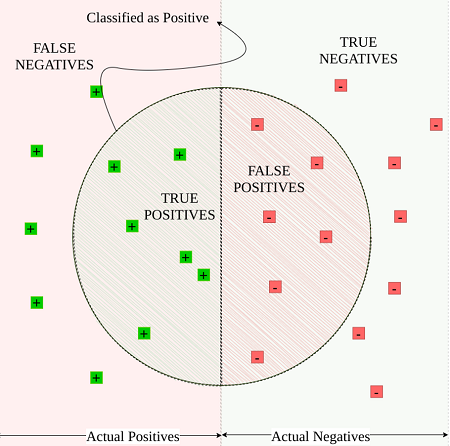

Cách đơn giản và hay được sử dụng nhất là accuracy (độ chính xác). Cách đánh giá này đơn giản tính tỉ lệ giữa số mẫu dự đoán đúng và tổng số mẫu trong tập dữ liệu. Công thức:
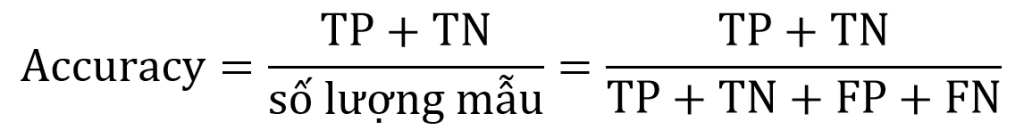

Giả sử độ accuracy = 90% có nghĩa là trong số 100 mẫu thì có 90 mẫu được phân loại chính xác. Tuy nhiên đối với tập dữ liệu kiểm thử không cân bằng (nghĩa là số positive lớn hơn rất nhiêu so với negative) thì đánh giá có thể gây hiểm nhầm.
Quay lại với ví dụ phân loại email spam. Xem xét trên 100 email nhận được, có 90 email trong số là spam. Trong trường hợp này, mô hình chỉ có thể phân loại ra một kết quả duy nhất là spam thì cũng có thể đạt accuracy là 90%.
Tương tự, trong trường hợp phát hiện giao dịch gian lận, chỉ một phần rất nhỏ các giao dịch là gian lận. Nếu mô hình phân loại dự đoán toàn bộ là không gian lận thì việc đánh giá mô hình vẫn có độ chính xác gần như 100%.
2.2 Precision and Recall
Với bài toán phân loại mà tập dữ liệu của các lớp chênh lệch nhau rất nhiều (mất cân bằng), thường sử dụng phương pháp đánh giá Precision-Recall.
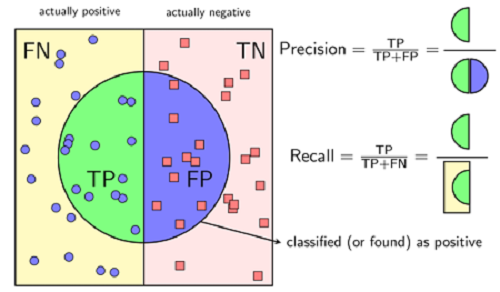

Precision được định nghĩa là tỉ lệ số mẫu true positive trong số những mẫu được phân loại là positive (TP + FP). Với precision = 0,9 có nghĩa là mô hình dự đoán đúng 90 mẫu trong 100 mẫu mô hình dự đoán là positive
Recall được định nghĩa là tỉ lệ số mẫu true positive trong số những điểm thực sự là positive (TP+FN). Với recall = 0,9 có nghĩa là mô hình dự đoán đúng 90 mẫu trong 100 mẫu thực sự là positive.
Precision cao đồng nghĩa độ chính xác của các mẫu đúng là cao. Recall cao đồng nghĩa với việc bỏ sót các mẫu thực sự positive là thấp. Một mô hình phân lớp tốt là mô hình có cả Precision và Recall đều cao, tức càng gần một càng tốt.
2.3 F-1 Score
F-1 score là trung bình điều hòa (harmonic mean) của precision và recall, có tầm quan trọng tương tự như với FNs và FPs. Cụ thể:
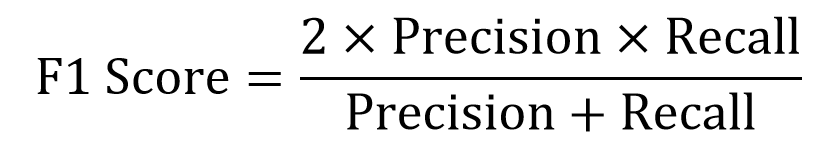

F-1 score càng cao tương ứng precision và recall càng cao, mô hình phân loại càng tốt.
2.4 Multi-Class Classification (phân loại đa lớp)
Gọi là phân loại đa lớp khi có số lớp cần phân loại lớn hơn 2. Việc đánh giá mô hình cũng tương tự như khi đánh giá mô hình nhị phân.
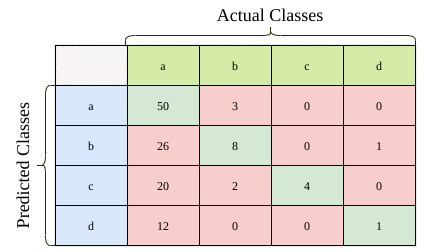

Giả sử kết quả dự đoán của mô hình phân loại được thể hiện ở ma trận confusion trình bay ở trên. Có tổng 127 mẫu. Bây giờ hãy đánh giá mô hình.
Nhớ rằng, accuracy là tỉ lệ phân loại đúng với tổng số mẫu, nằm trên đường chéo. Để có accuracy, lấy tổng số lượng phân loại đúng chia với tổng số mẫu.
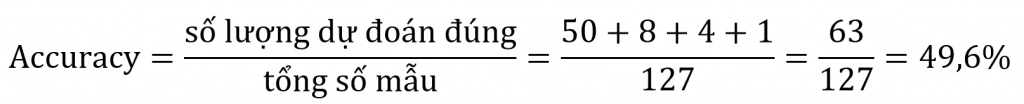

Như vậy, mô hình phân loại đã phân loại chính xác gần ½ số mẫu.
Tính toán Precision và Recall sẽ phức tạp hơn so với phân loại nhị phân. Không thể nói Precision hay Recall tổng thể của cả mô hình phân loại mà sẽ tính precision và recall ở mỗi lớp riêng biệt.
Mỗi lớp, cần xác định được TP, TN, FP và FN. Từ đó xác định được precision và recall:
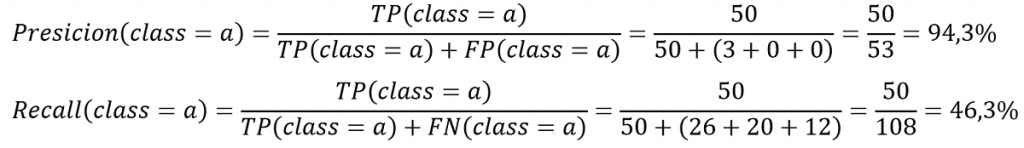

Tương tự, có thể tính precision và recall ở các lớp còn lại:
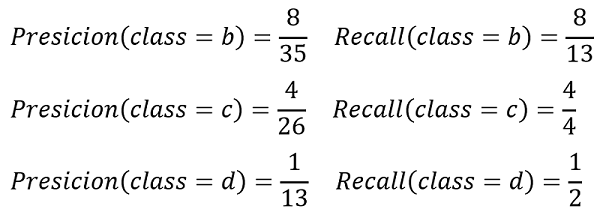

Chúc các bạn thành công!
P.C.A.Huy
AI R&D Team
Bài viết liên quan:
1. Giải pháp của ST giúp triển khai mạng Nơ-ron nhân tạo trên STM32
2. X-CUBE-AI: Gói phần mềm AI cho STM32CubeMX
3. Hướng dẫn triển khai mạng Nơ-ron nhân tạo trên vi điều khiển STM32
[HỌC ONLINE TẠI TAPIT: LẬP TRÌNH VI ĐIỀU KHIỂN STM32, VI XỬ LÝ ARM CORTEX – M]
4. Xem thêm Tổng hợp các bài hướng dẫn Lập trình vi điều khiển STM32 tại đây.
5. Xem thêm Tổng hợp hướng dẫn Internet of Things với NodeMCU ESP8266 và ESP32 tại đây.
Tài liệu tham khảo:
[1] https://www.baeldung.com/cs/classification-model-evaluation
[2] https://machinelearningcoban.com/2017/08/31/evaluation/