



Học máy (Machine learning) là một tập con (subset) của trí tuệ nhân tạo. Vậy mục tiêu của học máy là gì? Nó khác biệt thế nào so với thuật toán truyền thống thông thường và những khái niệm nào liên quan đến học máy? Tại bài viết chia sẻ này, mình sẽ cùng các bạn giải đáp những câu hỏi trên.
1. Hiểu về học máy
- Học máy bao gồm nhiều loại thuật toán và phương pháp đào tạo khác nhau sử dụng xác suất thống kê, đại số tuyến tính để phân tích và trực quan hóa dữ liệu theo nhiều cách khác nhau. Mục tiêu của Thuật toán học máy là trích xuất các tính năng có liên quan từ dữ liệu đào tạo để tạo mô hình dự đoán cho dữ liệu mới.
- Thuật toán chỉ trở nên thông minh sau khi được đào tạo trên dữ liệu phù hợp. Chẳng hạn, không có mức độ phức tạp của thuật toán nào có thể dự đoán lỗi máy mà không có ví dụ về lỗi để học hỏi.
- Các thuật toán học máy bắt đầu học từ trạng thái con số không, mà không có bất kỳ ngữ cảnh nào. Ví dụ, một động cơ điện dừng có thể hoàn toàn bình thường trong một số trường hợp nhưng lại bất thường trong một số trường hợp khác. Ví dụ đơn giản này minh họa tầm quan trọng của ngữ cảnh và nhu cầu về dữ liệu huấn luyện đủ đa dạng để thuật toán học được ngữ cảnh.
2. So sánh thuật toán truyền thống và học máy
Một các đơn giản hơn để hiểu tổng quát về học máy là So sánh Thuật toán truyền thống và Thuật toán học máy.


Hình 1. Mô hình thuật toán truyền thống
Thuật toán truyền thống (Traditional algorithm): Tham số và quy tắc của hệ thống được thiết kế bởi con người. Thuật toán nhận dữ liệu đầu vào và cho ra kết quả
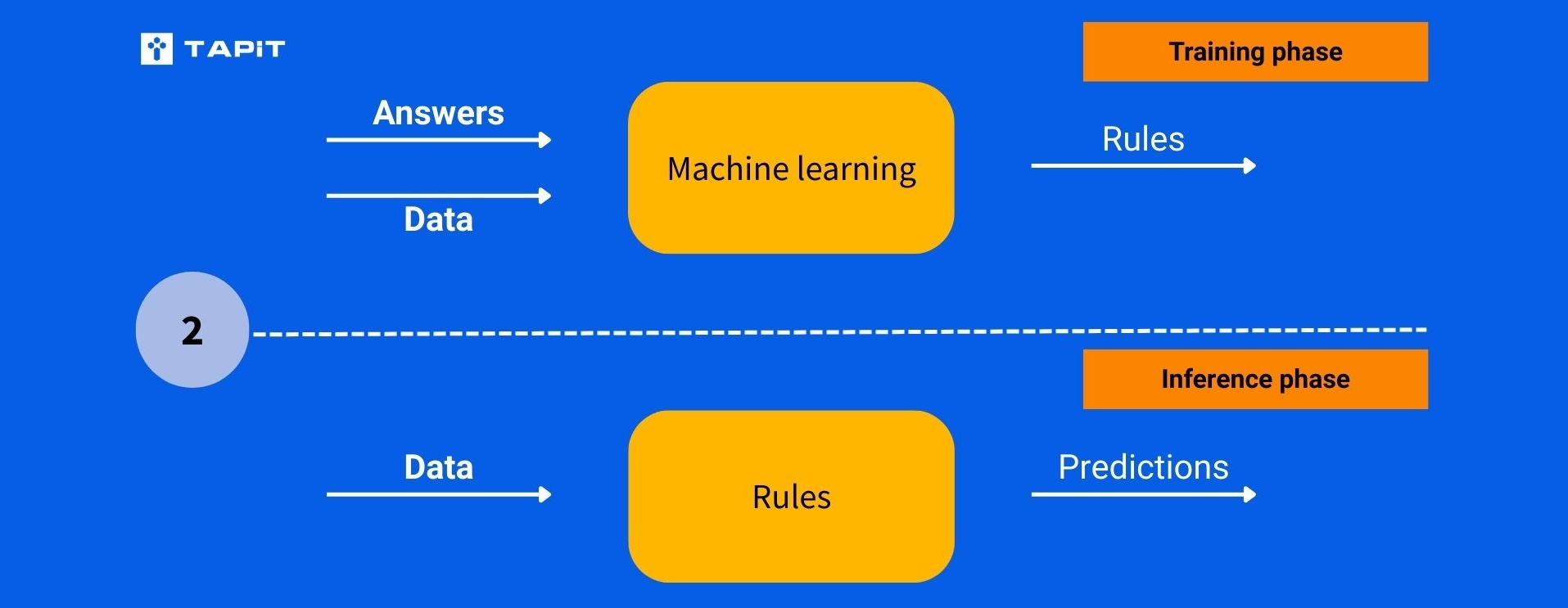

Hình 2. Mô hình thuật toán học máy
Thuật toán học máy (Machine learning algorithm): Thuật toán huấn luyện học máy tự động phát triển các tham số và quy tắc dựa trên dữ liệu đầu vào. Trong giai đoạn huấn luyện, thuật toán học máy phát triển các quy tắc để phân loại dữ liệu đầu vào một cách chính xác nhất có thể. Các quy tắc phát triển trong giai đoạn huấn luyện là một mô hình toán học hoặc thống kê và thường được gọi là mô hình AI (AI model).
Các mô hình – model sau đó có thể được sử dụng để dự đoán các câu trả lời và giá trị từ dữ liệu mới mà chưa bao giờ được thấy trong quá trình huấn luyện. Quá trình này được gọi là suy diễn (inference) vì mô hình đang cố gắng suy ra các giá trị hoặc ý nghĩa từ dữ liệu mới. Nếu các quy tắc hoạt động tốt trong nhiệm vụ này (với dữ liệu đầu vào chưa từng thấy), thì chúng ta có thể nói rằng mô hình AI đang tổng quát (generalization) tốt.
3. Các khái niệm cơ bản trong Học máy
- Dữ liệu huấn luyện (Training Data): Là những dữ liệu đầu vào như văn bản, hình ảnh, video, audio, dữ liệu dạng bảng, cảm biến… được gán nhãn kết quả đầu ra.
- Biểu diễn/ mã hóa dữ liệu (Representation): Nhiệm vụ mã hóa, trích xuất đặc trưng từ dữ liệu. Biến dữ liệu thô (hình ảnh, văn bản, âm thanh) thành các đặc trưng (features) mà máy tính có thể hiểu được (thường là các vector số). Điều quan trọng của biểu diễn dữ liệu việc lựa chọn những thông tin (đặc trưng) thực sự có liên quan và có ý nghĩa đối với mục tiêu dự đoán.
- Đánh giá (Evaluation): Chúng ta cần một thước đo để biết mô hình nào là “tốt” hay “xấu”. Việc đánh giá kết quả mô hình giúp chúng ta có thể đưa ra những hiệu chỉnh hoặc lựa chọn được mô hình tối ưu nhất.
- Tối ưu hoá (Optimization): Nếu Evaluation nói cho chúng ta biết “Mô hình đang tệ ở đâu”, thì Optimization là “Cách để sửa nó“. Cập nhật các tham số của mô hình để giảm thiểu sai số, giúp mô hình cải thiện độ chính xác.
Tài liệu tham khảo:
Chúc các bạn thành công!
Thuong Nguyen