





Ngày nay, xe là phương tiện giao thông phổ biến nhất, giúp mọi người đi lại nhanh chóng. Mỗi chiếc xe đều có đăng ký một biển số để lưu thông trên đường, biển số là duy nhất. Vấn đề là quản lý những chiếc xe này như thế nào? Ví dụ như ở bãi giữ xe, giao thông trên đường. Tình trạng kẹt xe ở bãi giữ xe là rất được quan tâm. Tuy có nhiều biện pháp để khắc phục nhưng lưu lượng xe ra vào là rất đông là ở các siêu thị, khu công nghiệp ở đề tài này là ở các trạm thu phí. Nhân viên đã làm việc nhanh hết khả năng có thể. Với tình hình cấp thiết như vậy đòi hỏi cần có một công cụ trợ giúp nhân viên thu thập dữ liệu để lưu trữ.
Trên thực tế việc quản lý này chỉ dùng bằng mắt người mà quan sát hoặc phiếu giấy rồi các dữ liệu đó cũng biến mất theo trí nhớ của người đó. Khi có vấn đề xảy ra thì họ không biết nên kiểm tra từ đầu. Hoặc với cách quản lý bằng việc chụp ảnh rồi lưu trữ thì gặp khó khăn về bộ nhớ.
Vì vậy nhằm cải thiện tình hình cần có hệ thống hỗ trợ và đó là hệ thống nhận diện biển số xe. Cụ thể hơn chính là đề tài: “ Tìm hiểu và thiết kế trạm kiếm soát xe lưu thông trên quốc lộ bằng phương pháp xử lý ảnh nhận dạng biển số”.
| Xử lý ảnh là gì? |
Con người thu nhận thông tin qua các giác quan, trong đó thị giác đóng vai trò quan trọng nhất. Những năm trở lại đây với sự phát triển của phần cứng máy tính, xử lý ảnh và đồ hoạ đó phát triển một cách mạnh mẽ và có nhiều ứng dụng trong cuộc sống. Xử lý ảnh và đồ hoạ đóng một vai trò quan trọng trong tương tác người máy.
Xử lý ảnh được xem như là quá trình thao tác ảnh đầu vào nhằm cho ra kết quả mong muốn. Kết quả đầu ra của một quá trình xử lý ảnh có thể là một ảnh “tốt hơn” hoặc một kết luận.
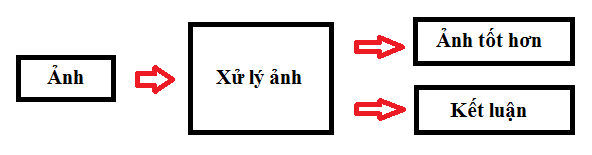
Hình 1. Quá trình xử lý ảnh

Ảnh có thể xem là tập hợp các điểm ảnh và mỗi điểm ảnh được xem như là đặc trưng cường độ sáng hay một dấu hiệu nào đó tại một vị trí nào đó của đối tượng trong không gian và nó có thể xem như một hàm n biến P(c1, c2,…, cn). Do đó, ảnh trong xử lý ảnh có thể xem như ảnh n chiều.
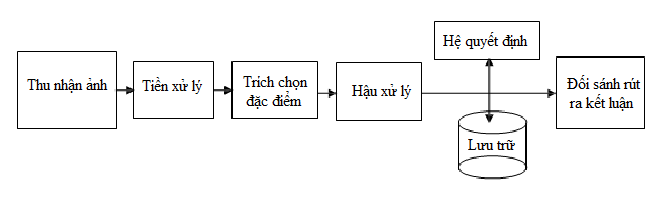
Hình 2. Các bước cơ bản trong một hệ thống xử lý ảnh

| Phạm vi đề tài |
- Nghiên cứu kỹ thuật nhận dạng biển số xe. Các đặc trưng Haar-like, mô hình cascade, công cụ nhận dạng chữ in Tesseract OCR.
- Nhận dạng trên biển số xe máy và ô tô ở Việt Nam.
| Mô hình hoạt động của trạm thu phí |
Thành phần cấu tạo
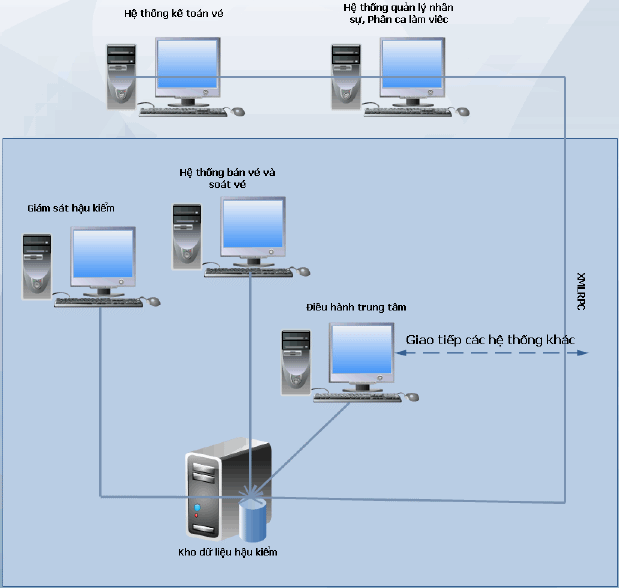
Hình 3. Sơ đồ hệ thống trạm thu phí đường bộ

- Hệ thống phần mềm tự động nhận dạng biển số
- Phát hiện xe hợp lệ vé tháng, vé quý hay vé lượt, xe ưu tiên
- Tự động đóng mở barie khi xe hợp lệ
- Hệ thống phần mềm giám sát các làn
- Hệ thống phần mềm hậu kiểm tìm kiếm
- Hệ thống phần mềm kho vé, nhân sự.
- Hệ thống thiết bị phần cứng hỗ trợ như camera, thiết bị kích hoạt, vòng loop,…
Nguyên tắc hoạt động
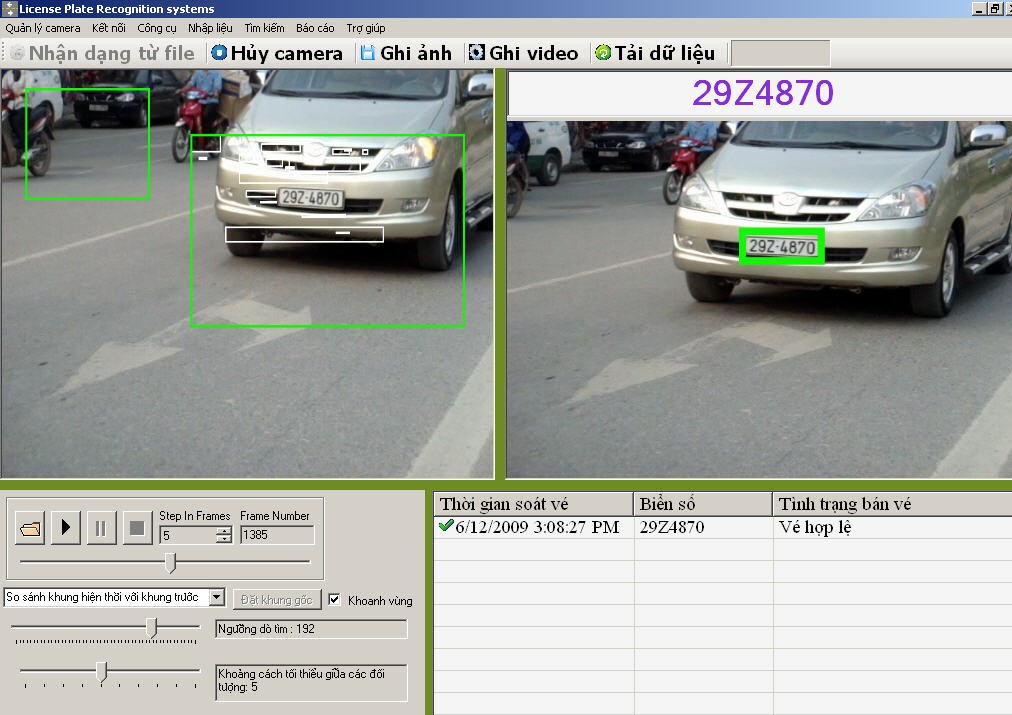
Hình 4. Chương trình demo của phần mềm trạm thu phí đường bộ



- Ảnh biển số được xử lý bằng phần mềm nhận dạng biển số(4 hoặc 5 số) với tốc độ 1,2s /1 ảnh.
- Hệ thống sẽ lưu lại ảnh biển số, biển số xe, đồng thời truy xuất cơ sở dữ liệu để lấy thông tin về trọng tải của xe.
- Hệ thống đọc dữ liệu mã vạch từ đầu đọc mã vạch trong cabin.
- Hệ thống đối chiếu mã vạch trên vé với trọng tải của xe để giám sát và phát hiện sai phạm trong quá trình bán và sử dụng vé.
- Tất cả hình ảnh biển số, toàn cảnh của xe lưu thông qua làn được lưu trữ với đầy đủ thông tin ngày, giờ lưu thông qua trạm.
- Mã barcode của vé mà người điều khiển phương tiện sử dụng để lưu thông qua trạm cũng đc lưu lại.
- Toàn cảnh các loại xe lưu thông qua trạm đều được ghi hình và lưu trữ trên hệ thống. Có thể xem lại hình ảnh của một tháng trước đó.
- Trong mỗi cabin bán vé đều có một camera giám sát 24/24h. Mọi hoạt động trong cabin đều được giám sát tại phòng điều hành.
- Hệ thống barrier sẽ tự động đóng mở cho xe đã mua vé hợp lệ được phép lưu thông qua làn.
- Có thể lựa chọn chế độ hoạt động của barrier là tự động hoặc bằng tay từ trên phần mềm giám sát.
- Mọi thông tin kiểm soát vé như giá vé, loại vé và vé có hợp lệ hay không, được hiển thị tức thời lên bảng led.
Đặc trưng của Haar-like
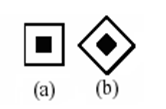
Đặc trưng Haar-like do Viola và Jones công bố năm 2001. Gồm 4 đặc trưng cơ bản, mỗi đặc trưng là sự kết hợp của hai hay ba hình chữ nhật “trắng” hay “đen” như sau:

Hình 5. Bốn đặc trung haar-like cơ bản.

Để sử dụng các đặc trưng này vào việc xác định đối tượng,4 đặc trưng Haar-like cơ bản được mở rộng và được chia làm 3 tập đặc trưng sau:
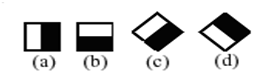
Hình 6. Đặc trưng cạnh.
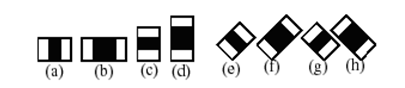
Hình 7. Đặc trưng đường.
Hình 8.Đặc trưng xung quanh tâm.



Dùng các đặc trưng trên, ta có thể tính được giá trị của đặc trưng Haar-like là sự chênh lệch giữa tổng của các pixel của các vùng đen và các vùng trắng như công thức sau:
f(x) = Tổng vùng đen (các mức xám của pixel) – Tổng vùng trắng (các mức xám của pixel)
Giá trị này so sánh với các giá trị của các pixel thô, các đặc trưng Haar-like có thể tăng/giảm sự thay đổi bên trong hay bên ngoài lớp, do đó sẽ làm cho bộ phân loại dễ hơn.
Để tính các giá trị của đặc trưng Haar-like, cần phải tính tổng của các vùng pixel trên ảnh. Nhưng để tính toán các giá trị của đặc trưng Haar-like cho tất cả các vị trí trên ảnh đòi hỏi chi phí khá lớn, không đáp ứng cho ứng dụng đòi hỏi tính run-time.
Viola và Jones đưa ra một khái niệm gọi là Integral Image, là một mảng 2 chiều với kích thước bằng với kích thước của ảnh cần tính các đặc trưng Haar-like, với mỗi phần tử của mảng này được tính bằng cách tính tổng của điểm ảnh phía trên (dòng-1) và bên trái (cột-1) của nó. Bắt đầu từ vị trí trên, bên trái đến vị trí dưới, bên phải của ảnh, việc tính toán này đơn thuần chỉ dựa trên phép cộng số nguyên đơn giản, do đó tốc độ thực hiện rất nhanh.

Hình 9. Cách tính Integral Image của ảnh

Sau khi tính được Integral Image, việc tính tổng các giá trị mức xám của một vùng bất kỳ nào đó trên ảnh thực hiện rất đơn giản theo cách sau:
Giả sử ta cần tính tổng các giá trị mức xám của vùng D như trong hình 10
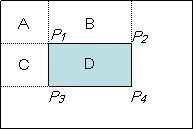
Hình 10. Vùng D trên ảnh

Ta có: D = A+B+C+D-(A+B)-(A+C)+A
Mặc khác:
A+B+C+D = P4, A+C=P3, A+B=P2, A=P1 (P1, P2, P3, P4 là các giá trị trên Integral Image)
⇒ D = P4 – P3 – P2 + P1
Để chọn các đặc trưng Haar-like dùng cho việc thiết lập ngưỡng, Viola và Jones sử dụng một phương pháp máy học được gọi là AdaBoost. AdaBoost sẽ kết hợp các bộ phân loại yếu để tạo thành một bộ phân loại mạnh. Với bộ phân loại yếu chỉ cho ra câu trả lời ít chính xác, còn bộ phân loại mạnh có thể đưa ra câu trả lời chính xác trên 60%.
| Xác định biển số nhờ giải thuật Casade of Classifiers trong OpenCV |
Với yêu cầu chạy trên các thiết bị điện thoại, máy ảnh, thiết bị có cấu hình yếu thì thuật toán Cascade of Classifiers ra đời. Nghĩa là “Phân lớp theo tầng”. Dựa trên những đặc trưng haar-like của đối tượng mà thuật toán tiến hành rút trích ra các đặc trưng của đối tượng. Do đối tượng nhận dạng có nhiều hình dạng khác nhau nên phải phân tầng nhận dạng. Ví dụ nhận diện biển số xe máy ở Việt Nam. Ngoài mã tỉnh, mã huyện, thì còn có loại 4 ký tự, loại 5 ký tự. Có loại viền dầy, loại viền mỏng, loại dán decal, loại có ký tự rõ ràng, loại ký tự bị mờ. Về góc chụp thì có hình vuông hình chữ nhật, hình tứ giác. Ánh sáng cũng ảnh hưởng làm nhiễu biển số.
Thuật toán Cascade of Classifiers tiến hành phân ra thành các giai đoạn (gọi là stage), các vùng hình chữ nhật nghi ngờ phải đạt ngưỡng đúng (threshold) của tất cả các giai đoạn được xác định là chứa đối tượng. Trong một giai đoạn có nhiều cây quyết định (decision tree) và đi theo nhánh của cây sẽ giúp cho việc xác định nhanh hơn rất nhiều.
Minh họa cấu trúc phân tầng như sau (ví dụ không nhất thiết giống như tập tin xml):
- Giai đoạn 1: ngưỡng 10%
- Đặc trưng 1 có ngưỡng 11%: qua giai đoạn tiếp theo
- Đặc trưng 2 có ngưỡng 9%: lớp âm
- Giai đoạn 2: ngưỡng 15%
- Đặc trưng 1 có ngưỡng 16%: qua giai đoạn tiếp theo
- Đặc trưng 2 có ngưỡng 14%: lớp âm
- Giai đoạn n: ngưỡng xx%
- Đặc trưng 1 có ngưỡng >xx%: lớp dương
- Đặc trưng 2 có ngưỡng <xx%: lớp âm
Số lượng giai đoạn và ngưỡng quyết định bởi dữ liệu học và các tham số khác do người dùng chỉ định. Để có thể nhận dạng thuật toán tiến hành lấy mẫu từ 2 tập dữ liệu: tập ảnh dương bao gồm ảnh chứa đối tượng và tập ảnh âm không chứa đối tượng. Tiến hành học dựa trên các ảnh này. Dữ liệu học càng nhiều thì nhận diện càng chính xác, bao gồm cả ảnh dương và ảnh âm, bù lại thì thời gian huấn luyện lâu hơn.
Nếu vùng nghi ngờ được xác định đúng là đối tượng thì thuật toán trả về những khung hình chữ nhật. Ngược lại thuật toán sẽ không xác định được đối tượng và trả về false.
| Nhận dạng ký tự với Tesseract OCR |
Sơ lượt về Tesseract
Tesseract bộ công cụ nhận diện ký tự quang học (Optical Character Recognition – OCR) thương mại, được phát triển bởi hãng HP giữa những năm 1985 và 1995. Nó được biết như là một phần mềm thêm vào cho dòng sản phẩm máy quét của HP. Trong giai đoạn này, nó vẫn còn rất sơ khai và chỉ được dùng để cải thiện chất lượng của các bản in. Nó được phát triển cho đến năm 1994 thì ngưng. Sau khi cải thiện độ chính xác, nó được HP đưa vào cuộc kiểm tra thường niên về độ chính xác của các công cụ OCR và nó đã thể hiện được sự vượt trội của mình. Sau đó, được mở mã nguồn vào năm 2005 và phát triển tại Google.
Cấu trúc của Tesseract
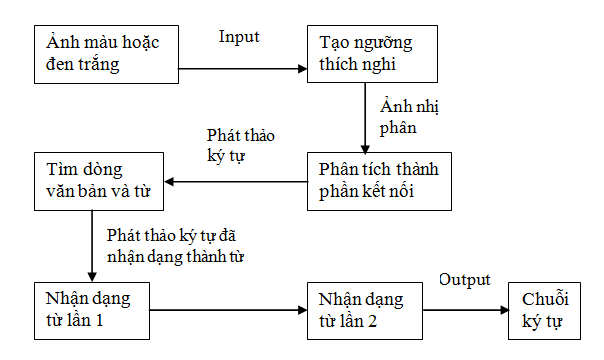
Hình 11. Cấu trúc Tesseract

Tạo ngưỡng thích nghi giúp loại bỏ các yếu tố nền của hình ảnh (ví dụ: ánh sáng, bóng, …) và giúp phân tích các pixel thành ảnh nhị phân.
Nhận dạng được tiến hành qua một quá trình với hai lần nhận dạng. Lần thứ nhất, nhận ra lần lượt từng từ. Mỗi từ có nghĩa là đạt yêu cầu, được thông qua và được lưu vào dữ liệu. Lần thứ hai, khi phân loại thích ứng, công cụ sẽ nhận dạng lại các từ không được nhận dạng tốt ở lần trước đó.
Xác định dòng và từ nhằm mục đích làm giảm sự mất thông tin khi nhận dạng ảnh nghiêng. Tesseract nhận biết dòng văn bản nhờ vào các dòng cơ sở. Nhận dạng từ là quá trình phân tích một từ và phụ thuộc vào từ được chia ra thành các ký tự.
Phiên bản Tesseract 3.02, cú pháp sử dụng:
tesseract imagename outputbase [-l lang] [-psm pagesegmode] [configfile…]
Trong đó:
- imagename là tên tập tin đầu vào
- outputbase là tập tin đầu ra. Ví dụ: output.txt lang là ngôn ngữ cần nhận dạng
- Pagesegmode là các lựa chọn từ 0-10. ý nghĩa: để tesseract chỉ chạy một tập hợp con của phân tích bố trí và giả định một hình thức nhất định của hình ảnh
- Configfile là tên của một cấu hình để sử dụng như: hocr,pdf…
| Giới thiệu chung về chương trình |
Phần cứng

Hình 12. Arduino Uno R3

- Arduino UNO có thể sử dụng 3 vi điều khiển họ 8bit AVR là ATmega8, ATmega168, ATmega328. Bộ não này có thể xử lí những tác vụ đơn giản như điều khiển đèn LED nhấp nháy, xử lí tín hiệu cho xe điều khiển từ xa, làm một trạm đo nhiệt độ – độ ẩm và hiển thị lên màn hình LCD,…
- Arduino UNO có thể được cấp nguồn 5V thông qua cổng USB hoặc cấp nguồn ngoài với điện áp khuyên dùng là 7-12V DC và giới hạn là 6-20V. Đối với chương trình đang sử dụng là thông qua cổng USB để cấp nguồn và kết nối với máy tính.
- Mạch của chương trình sử dụng mạch Arduino UNO sử dụng vi điều khiển ATmega328 kết hợp với module matrix 16×32
| Thiết kế và xây dựng mô hình hệ thống |
Thiét kế giao diện
Dùng Visual Studio 2015 tạo giao diện như sau:
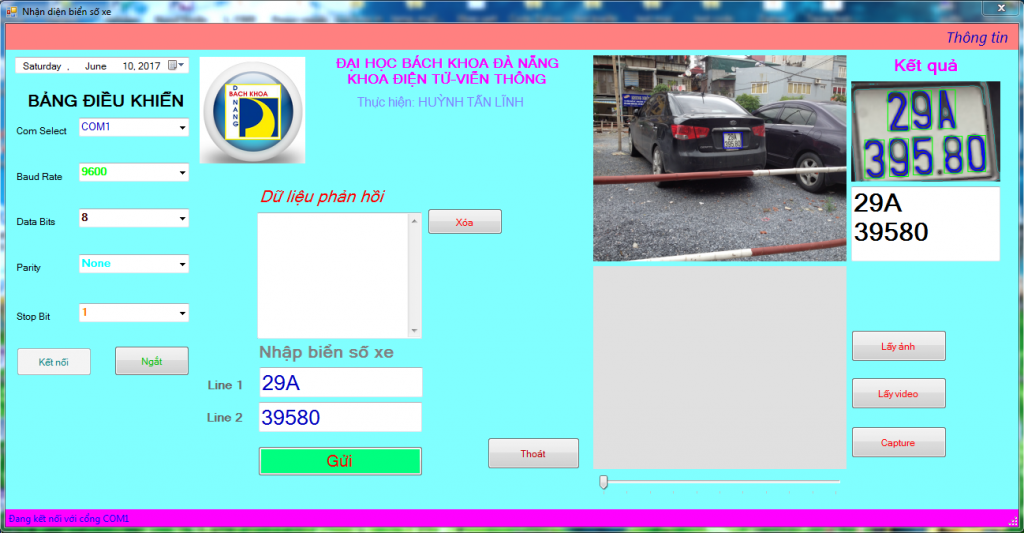
Hình 13. Giao diện chương trình

Sơ đồ thuật toán
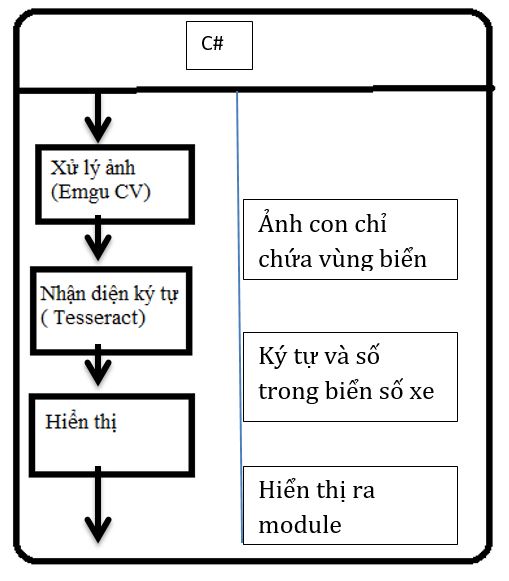
Hình 14. Sơ đồ thuật toán

Hệ thống của chúng ta có đầu vào đơn giản từ những bức hình chụp phương tiện cần nhận diện biển số xe. Sau đó, bức hình sẽ được xử lí nhằm tìm ra vùng chứa biển số xe. Tiếp theo Tesseract ORC engine sẽ nhận diện được kí tự trong vùng chứa biển số xe và đưa vào CSDL để xử lí.
Sơ đồ thuật toán xử lý chung của Arduino
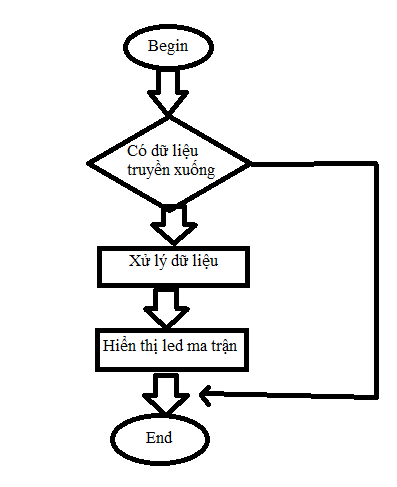
Hình 15. Sơ đồ thuật toán xử lý chung của arduino

Đầu tiên, ta sẽ kiểm tra có dữ liệu truyền xuống không, nếu không thì kết thúc chương trình, nếu có thì ta đưa vào xử lý dữ liệu và hiển thị lên led matrix, sau đó mới kết thúc chương trình.
Sơ đồ thuật toán hiển thị led ma trận
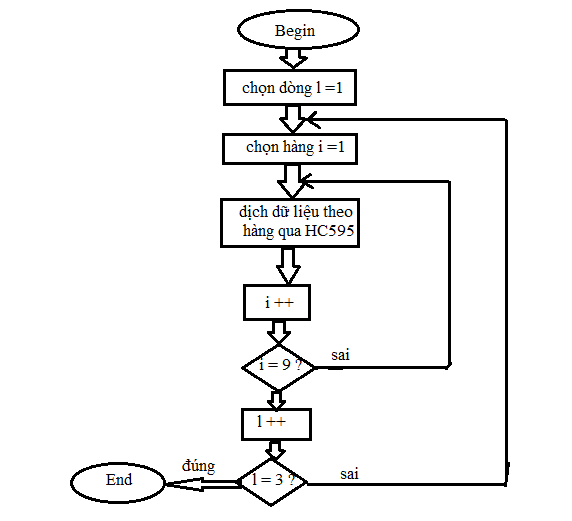
Hình 16. Sơ đồ thuật toán hiển thị led ma trận

Đầu tiên, ta chọn dòng trên với L=1 để hiển thị, bắt đầu vào ta sẽ chọn i=1 để quét led, tiếp theo đó dữ liệu chờ ở chân 14 của IC74595 sẽ được đẩy qua IC và hiển thị lên hàng đầu tiên của led matrix. Tương tự như vậy, ta tăng i để bắt đầu xuất dữ liệu qua hàng thứ 2, thứ 3,… đồng thời ta sẽ kiểm tra nếu i=9 thì nhảy qua tăng L=2 để bắt đầu quét led hàng dưới và vẫn tương tự như trên, ta sẽ bắt đầu lại từ i=1 để quét led từ dòng 1 và kiểm tra nếu L=3 thì kết thúc quá trình hiển thị.
| Demo |

Một trong 2 đề tài chia sẻ TAPIT Share Contest của trưởng ban giám khảo
Huỳnh Tấn Lĩnh!