

Trí tuệ nhân tạo đang trở thành một xu hướng phát triển mới nổi bật trong mảng thiết bị nhúng và IoT (máy tính nhúng, vi điều khiển trong hệ thống nhúng, sản phẩm IoT). Điều này được thể hiện rõ ràng qua các thiết bị, sản phẩm như camera an ninh, hệ thống xử lý các cảm biến trên ôtô, máy bay không người lái, cảm biến thông minh… Và để nhúng được các mô hình học sâu, trí tuệ nhân tạo vốn chỉ có thể chạy trên các hệ thống máy tính đồ sộ hoặc ít nhất là trên các máy tính cá nhân lên thiết bị vi điều khiển thì một thuật ngữ là “Edge AI” ra đời. Edge AI đơn giản là chỉ các mô hình AI được tối ưu hoá để có thể chạy trực tiếp trên các thiết bị đầu cuối (vòng đeo tay, điện thoại thông minh, máy tính nhúng,…). Từ Edge ở đây là chỉ các thiết bị gần với người dùng hơn có khả năng xử lý mô hình AI trực tiếp trên bộ xử lý của thiết bị thay vì phải gửi dữ liệu về một máy chủ để xử lý rồi trả kết quả về. Điều này cho phép xử lý được mô hình AI trong thời gian thực.
Đối với hãng STMicroelectronics, một công ty thiết kế và sản xuất dòng chip vi điều khiển STM32 nổi tiếng. STM32 có những đặc tính phù hợp để chạy Edge AI như hiệu năng cao (so với các dòng vi điều khiển nhúng khác), năng lượng tiêu thụ thấp, số lượng ngoại vi phong phú cho phép giao tiếp đọc nhiều loại cảm biến,… Và hãng STMicroelectronics trong những năm gần đây đã liên tục cho ra các phiên bản X-CUBE-AI mới. Đây là một gói phần mềm giúp việc triển khai mô hình học sâu trên vi điều khiển một cách vô cùng dễ dàng.
Trong bài viết này, mình sẽ chỉ thực hiện hướng dẫn các bước để nhúng một mô hình học sâu (thường có đuôi .h5, .tflite) xuống các kit phát triển STM32 để nhận diện âm thanh. Các bước hướng dẫn, giới thiệu về các quy trình tiền xử lý âm thanh để huấn luyện hay các bước để huấn luyện mô hình học sâu, mời mọi người tham khảo phần tham khảo mục [3] và [4].
Tham khảo
- Hướng dẫn sử dụng phần mềm STM32CubeIDE để debug code:
[1] https://tapit.vn/download-debug-code-su-dung-stm32cubeide/ - Đọc ADC sử dụng DMA:
[2] https://tapit.vn/doc-adc-nhieu-kenh-tren-smt32-su-dung-dma/ - Triển khai mạng nơ-ron trên vi điều khiến STM (chỉ áp dụng cho các gói X-CUBE-AI 5.2.0 trở về trước):
[3] https://tapit.vn/huong-dan-trien-khai-mang-no-ron-nhan-tao-tren-vi-dieu-khien-stm32/ - Huấn luyện mô hình học sâu với Keras:
[4] https://www.tensorflow.org/tutorials/audio/simple_audio?hl=vi - Cấu hình clock và tác dụng các miền clock của STM32 với STM32CubeIDE (Tiếng Anh):
[5] https://www.youtube.com/watch?v=Ntmgk2KnRRA - Reference Manual của STM32F746:
[6] https://www.st.com/resource/en/reference_manual/rm0385-stm32f75xxx-and-stm32f74xxx-advanced-armbased-32bit-mcus-stmicroelectronics.pdf - Datasheet của STM32F746:
[7] https://www.st.com/resource/en/datasheet/stm32f746zg.pdf - Giải thích về biến đổi Log_Mel (Tiếng Anh):
[8] https://www.youtube.com/watch?v=9GHCiiDLHQ4 - File code “main.c”:
[9] https://drive.google.com/file/d/1Unkl23aimdtQoS4yBCuLHZnjHzlDxXBj/view?usp=sharing - Getting Started with X-CUBE-AI:
[10] https://www.st.com/resource/en/user_manual/dm00570145-getting-started-with-xcubeai-expansion-package-for-artificial-intelligence-ai-stmicroelectronics.pdf - Hướng dẫn sử dụng mô-đun Sparkfun ADMP401:
[11] https://learn.sparkfun.com/tutorials/mems-microphone-hookup-guide/all - Sparkfun ADMP401:
[12]https://learn.sparkfun.com/tutorials/mems-microphone-hookup-guide/all (ADMP401)
https://cdn.sparkfun.com/assets/8/e/7/e/b/DS-000021-v1.22.pdf (biến thể ICS-40180 của ADMP401 do InvenSense sản xuất)
Chuẩn bị
- Phần mềm STM32CubeIDE: https://www.st.com/en/development-tools/stm32cubeide.html
- Thư viện arm_math: https://drive.google.com/file/d/1lSGDVhORB5yqtSqTz4DI_Md8wQfOrKS7/view?usp=sharing
Thư viện này hỗ trợ các hàm tính toán trong quá trình xử lý tín hiệu âm thanh đầu vào và xử lý các phép tính của mô hình học sâu. Thư viện này rất hữu dụng khi hỗ trợ đầy đủ các phép biến đổi Fourier, phép nhân số thực nhanh, …
- Thư viện xử lý âm thanh: https://drive.google.com/file/d/1CZU_HUEPYk5-s1Ll54MUAjDxyZQU0_2-/view?usp=sharing
Thư viện này hỗ trợ việc triển khai các bộ lọc, chuyển đổi âm thanh từ miền thời gian sáng tần số và tạo phổ log-mel cho một mẫu âm thanh.
- Mô hình học sâu: https://drive.google.com/file/d/1mVftDSwaUeDdrq4dUaD8MW2fK4jiZeRy/view?usp=sharing
Mô hình này phân biệt 3 lớp âm thanh: tiếng cưa máy, tiếng động cơ (của các loại phương tiện như ô tô, xe máy), âm thanh nền (tiếng suối, chim hót, nước, …)
Hướng dẫn
Trước khi thực hiện các bước dưới, hãy đọc các phần tham khảo bên trên để nắm các bước cơ bản trong tạo project, đọc ngoại vi, …
1. Khởi tạo Project với gói phần mềm X-CUBE-AI
- Tạo 1 project với VĐK STM32F746ZGT6U (chọn VĐK phù hợp với con của bạn đang dùng)


Hình 1: Giao diện cấu hình để sinh code
- Kích hoạt “Debug: Serial Wire” để thuận tiện cho việc debug:
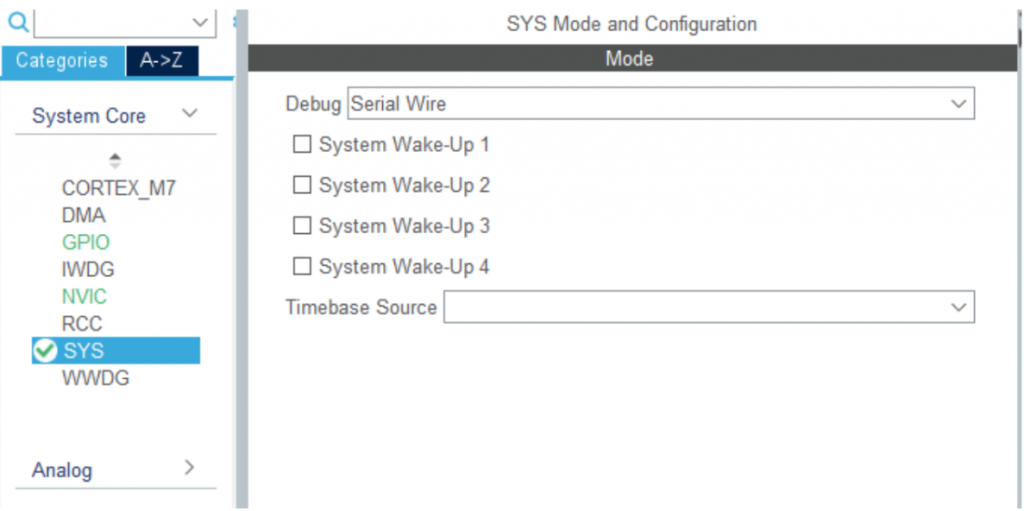

- Kích hoạt gói phần mềm X-CUBE-AI bằng cách kích vào “Software Packs” chọn “Select Components” và chọn X-CUBE-AI. Sau đó bấm Install và set các mục như hình dưới. Tiếp theo chọn OK để tải và cài đặt gói phần mềm (khoảng 500 MiB cho phiên bản 7.3.0).
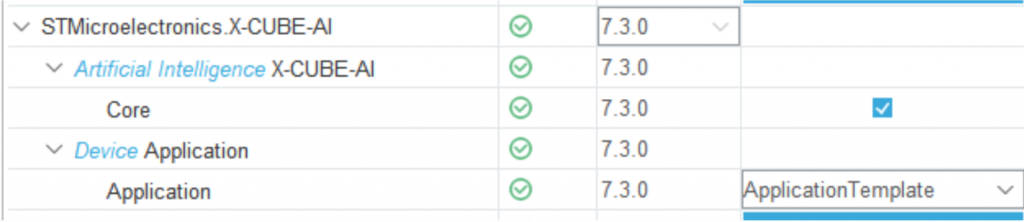

- Đến đây ta đã cài đặt xong gói X-CUBE-AI vào project, bây giờ ta cần phải đưa mô hình học sâu ở định dạng “.h5” vào để chuyển đổi thành các mô hình dưới dạng ngôn ngữ C. Chúng ta chọn mục “Software Packs” ở cột dọc bên tay trái và chọn “STMicroelectronics.X-CUBE-AI.7.3.0”
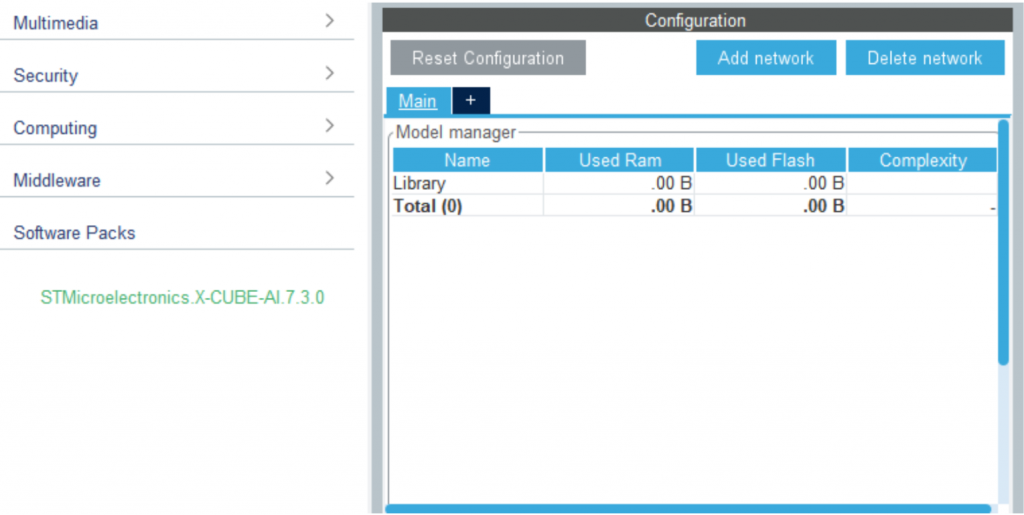

- Ta bấm vào dấu “+” bên cạnh chữ “Main” để tạo một “network”. Tiếp theo chọn “Browse…” và trỏ đến mô hình “.h5” ta tải ở trên. Các mục “Compression”, “Optimization”, “Validation” có thể để mặc định – có thể hiệu chỉnh sau nếu kết quả không mong muốn. Tiếp theo, các bạn bấm vào nút Analyze thì quá trình phân tích và chuyển đổi mô hình từ định dạng “.h5” thành các file “.c/.h” sẽ diễn ra. Lưu ý là quá trình này có thể nhanh chậm tùy vào độ phức tạp mô hình và cấu hình máy tính đang sử dụng.
- Ở trong hình 5, ô đỏ đánh dấu số 2:
- Mục “Compression” nói về mức độ nén mô hình (các trọng số trong c-model sẽ có thể bị làm tròn, giảm bớt độ chính xác hay thậm chí gói phần mềm còn có thể giảm bớt số trọng số).
- Mục “Optimization” là mục dùng để định hướng cho goi X-CUBE-AI khi convert từ mô hình ban đầu sáng c-model theo hướng tối ưu về bộ nhớ RAM hay là thời gian (Điều này có thể thực hiện bằng cách quản lý bộ nhớ cho các lớp activations).
- “Validation inputs/outputs”: Cho phép đưa các giá trị input và output tương ứng vào để kiểm tra mô hình có chạy như mong muốn hay không.
- Ngoài ra, các nút như “Show graph” cho phép xem và kiểm tra hoạt động của RAM khi chạy mô hình, nút “Validate on desktop” cho phép kiểm tra sai số của mô hình ban đầu so với mô hình đã chuyển đổi (do quá trình chuyển đổi, do quá trình nén mô hình) là bao nhiêu, nút “Validate on target” cũng tương tự như “Validate on desktop” nhưng yêu cầu kết nối UART với board để trao đổi dữ liệu với board (tác giả cũng chưa bao giờ dùng tính năng “Validate on target” này).
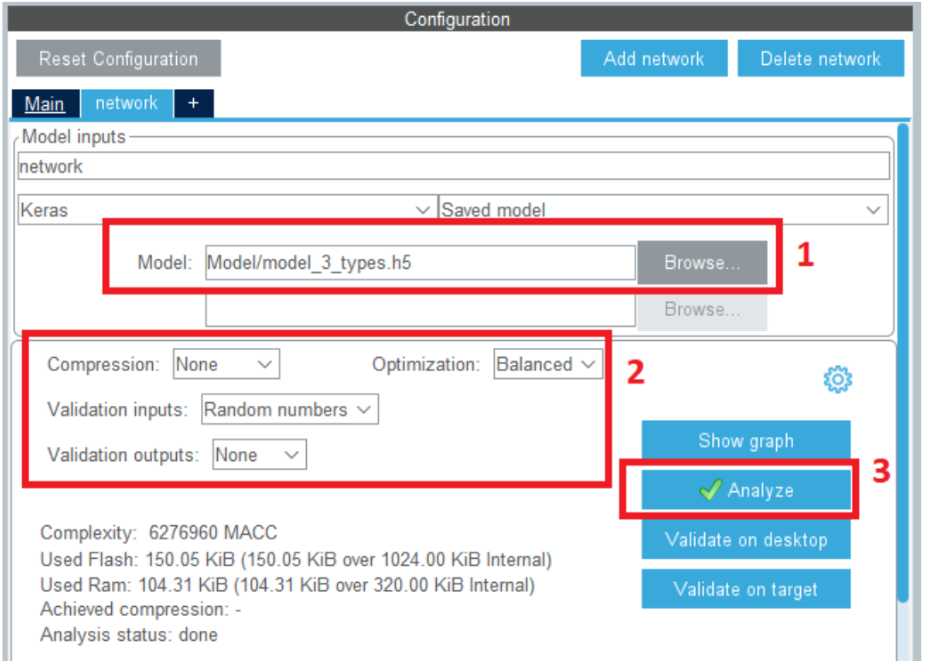

Hình 5: Chọn mô hình và các tham số hiệu chỉnh cho mô hình
- Đến đây nếu bạn bấm tổ hợp phím “Ctrl+S” thì code trong file main sẽ được sinh ra đồng thời một thư mục tên là X-CUBE-AI cũng được tạo ra trong thư mục project của bạn. Những file này chứa toàn bộ các tham số tạo ra trong quá trình training cũng như kích thước khởi tạo cho các lớp activations, input và output, các hàm (API) để sử dụng mạng NN đã huấn luyện.
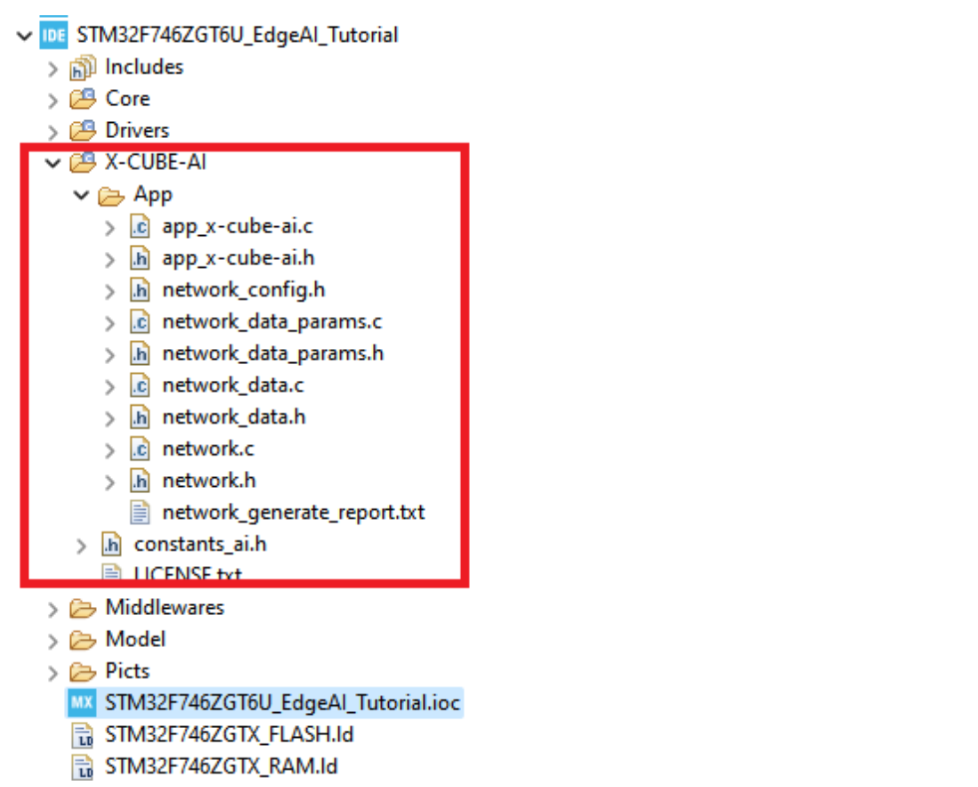

Hình 6: Thư mục X-CUBE-AI chứa các tham số và phép tính
- Đến đây, bước khởi tạo mạng học sâu cho project đã xong.
2. Chỉnh sửa cấu hình clock và ngoại vi ADC cho việc thu âm thanh
- Ở trong đề tài này, cảm biến âm thanh được sử dụng là cảm biến module Sparkfun MEMS microphone ADMP401 có các đặc điểm như sau:
- Thông số kỹ thuật: (tham khảo mục [12])
| Điện áp làm việc (V) | 3.3 |
| Dòng tiêu thụ (uA) | 250 |
| Băng thông -3dB (đối với tín hiệu âm thanh, không phải đối với tần số lấy mẫu) | 100Hz đến 15KHz |
- Trong đề tài này, các âm thanh như tiếng cưa máy, động cơ nằm trong khoảng từ 3KHz đến 4KHz thì mô-đun ADMP401 này hoàn toàn đáp ứng được.
- Ngoài ra, mô-đun ADMP401 này có đầu ra là tín hiệu analog (điện áp) từ 0V đến 3.3V. Khi mọi thứ xung quanh là yên tĩnh thì đầu ra của micro là 3.3V/2 = 1.65V. Tuy nhiên, chúng ta phải lưu ý là trong hướng dẫn của Sparkfun không nói ra điều kiện yên tĩnh là như thế nào (tham khảo mục [11]). Dù sao chúng ta có thể hiểu là nếu đưa âm thanh có dạng hình sin vào đầu thu của mic thì chân analog sẽ tạo ra 1 tín hiệu sin tương ứng và điện áp 1.65V đại diện cho cường độ sóng âm tại thời điểm nó bằng 0.
- Vì mô hình học sâu được sử dụng trong bài này được huấn luyện trên một tập âm thanh có tần số lấy mẫu 16 KHz nên chúng ta phải cấu hình clock và ADC sao cho âm thanh thu được từ MIC qua ADC phải có tần số bằng hoặc càng gần giá trị 16KHz càng tốt.
- Cấu hình clock: Vào tab Clock Configuration và cấu hình như hình dưới (hướng dẫn cách cấu hình các bạn coi mục Tham khảo [5]):
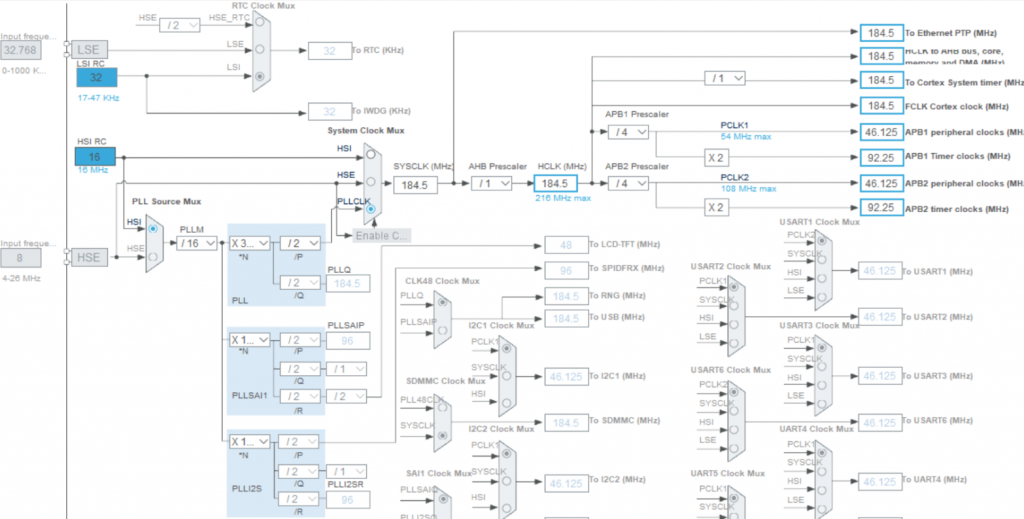
Hình 7: Cấu hình tần số hoạt động

- Cấu hình ADC: Ngoài clock ra, để đạt được tần số lấy mẫu sát với 16KHz, chúng ta còn phải cấu hình cho ngoại vi ADC và DMA như hình dưới (xem mục tham khảo [2] để rõ hơn về vấn đề cấu hình ADC)
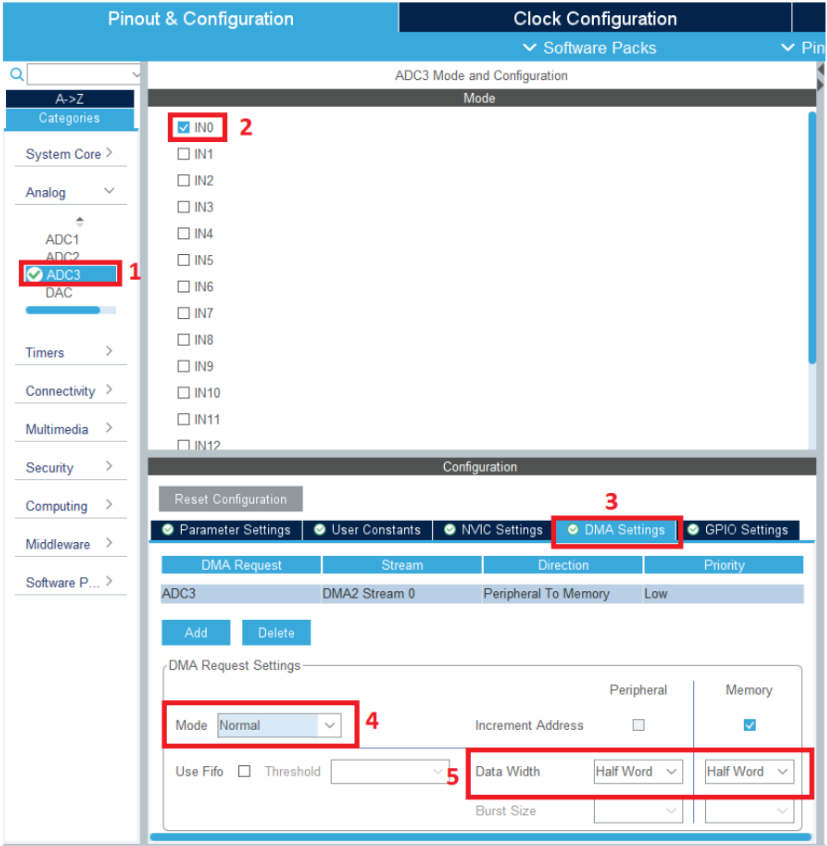

Hình 8: cấu hình kênh và DMA cho ngoại vi ADC
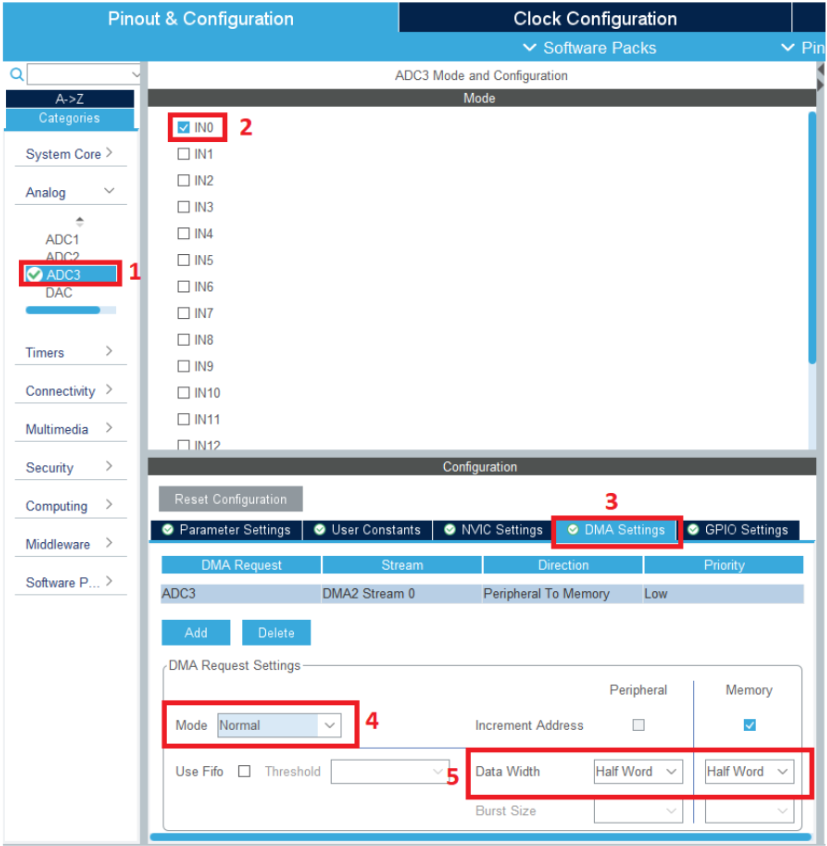

Hình 9: Cấu hình chia tần số và chế độ hoạt động cho ngoại vi ADC
- Các bạn tham khảo Reference Manual và Datasheet của VĐK STM32F746 tại mục tham khảo [6] và [7] thì có thể tính ra được tần số thu thập mẫu từ MIC qua ADC là:
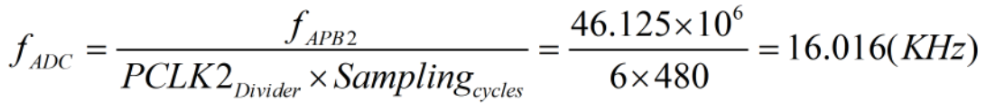

- Ta thấy sai số giữa tần số thu thập mẫu so với âm thanh chuẩn chỉ khoảng 0.1%. Hiển nhiên điều này chưa tính đến sai số của chính các bộ dao động nhưng sai số này thường rất nhỏ.
3. Cài đặt các thư viện
- Đến đây chúng ta hoàn tất các bước cài đặt và cấu hình phần cứng cũng như các gói phần mềm, bây giờ chúng ta cần phải cấu hình các thư viện để có thể sử dụng các API hỗ trợ trong việc xử lý âm thanh và mô hình học sâu.
- Đầu tiên ta sao chép các thư viện “Source_Arm_Math” và “STM32_AI_AudioPreprocessing_Library” cũng như các files “arm_math.h”, “math_helper.h” vào cây thư mục project. Sau khi sao chép các file thì cấu trúc thư mục project như hình:
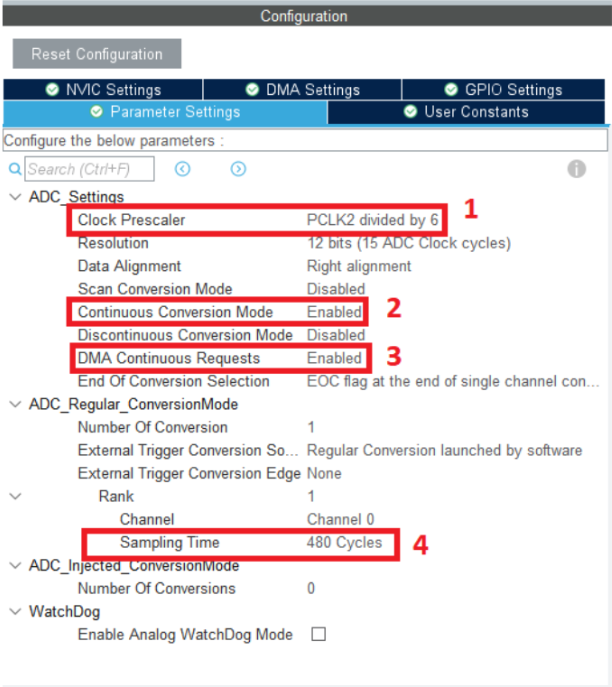

- Các bạn có thể sẽ phải chuột phải vào project và bấm refresh để IDE load lại đầy đủ cây thư mục.
- Chuột phải project chọn Properties và chọn “C/C++ General”, sau đó chọn “Paths and Symbols” và vào tab “Includes” rồi thêm các đường dẫn như hình dưới:
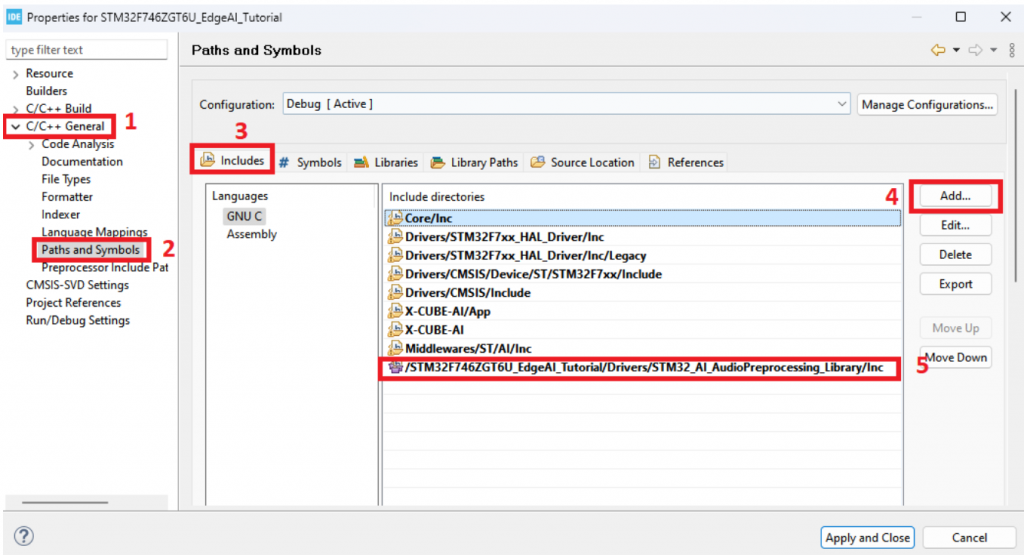

- Sau đó chọn qua tab Symbols và thêm các dòng sau:
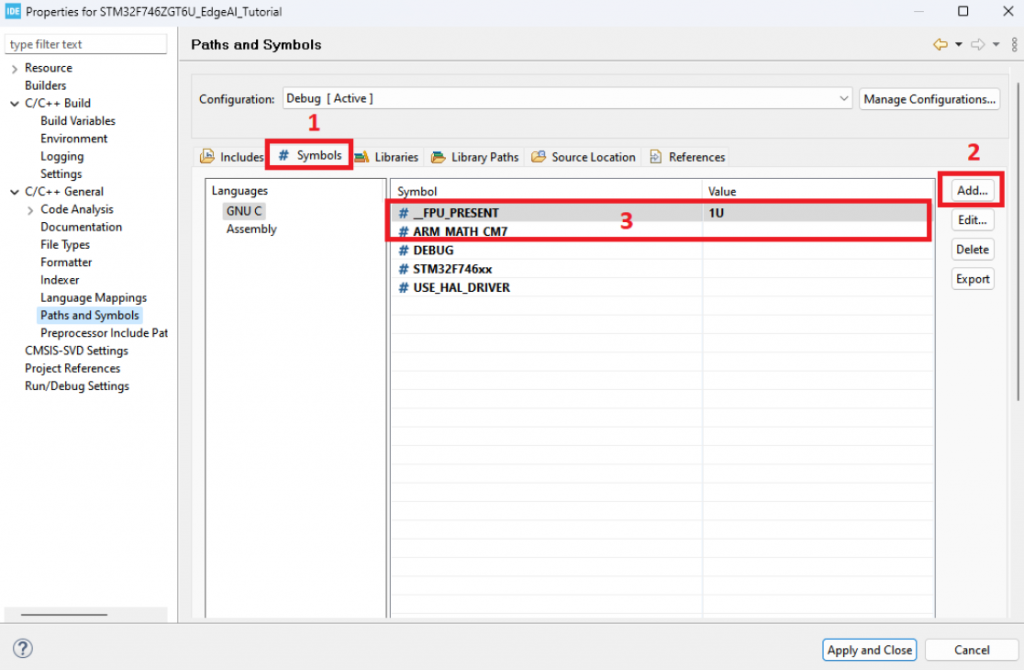

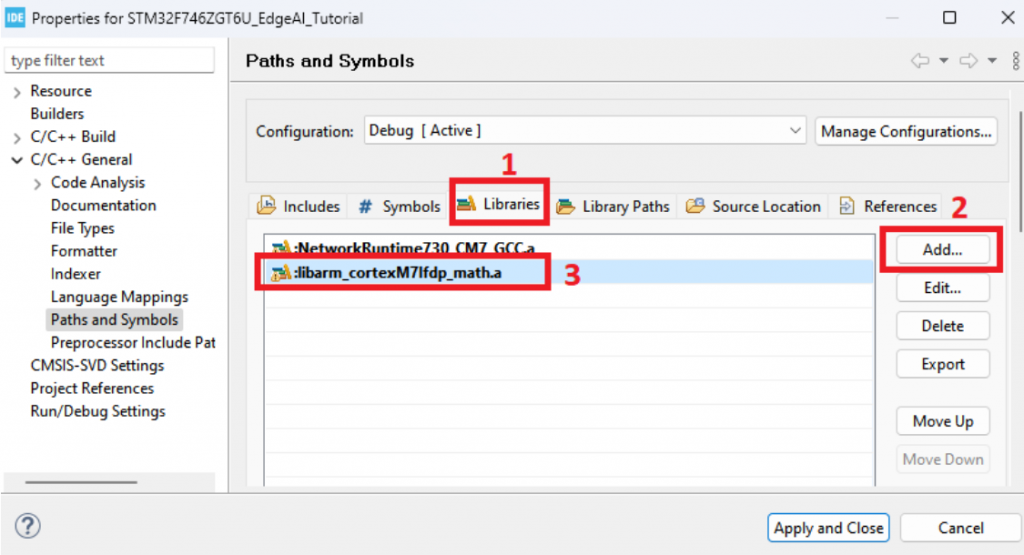
- Tiếp theo chọn tab “Libraries” và thêm thư viện “libarm_cortexM7lfdp_math.a” vào như hình:

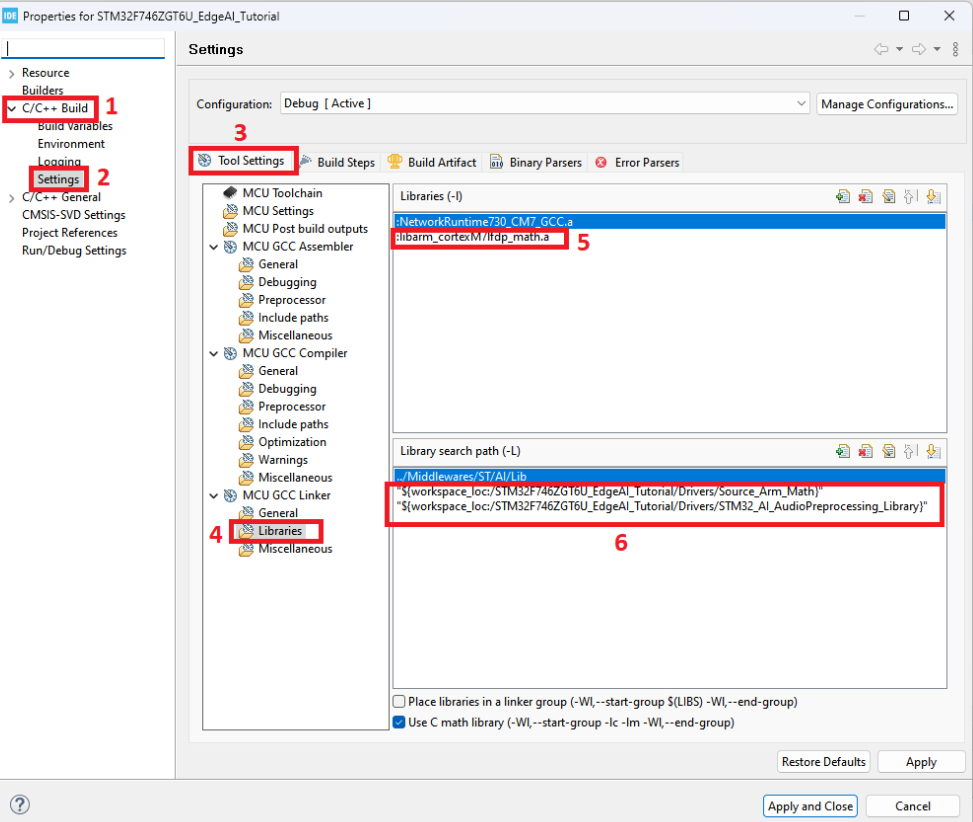
- Tiếp tục qua tab “Library Paths” và thêm các đường dẫn đến các thư mục chứa các thư viện như hình dưới:

- Đến đây việc thiết lập các đường dẫn đến các thư viện về cơ bản là xong tuy nhiên chúng ta cần phải thay đổi/kiểm tra một số thiết lập trong phần “C/C++ Build” thì mới update lại phải linker để build chương trình.
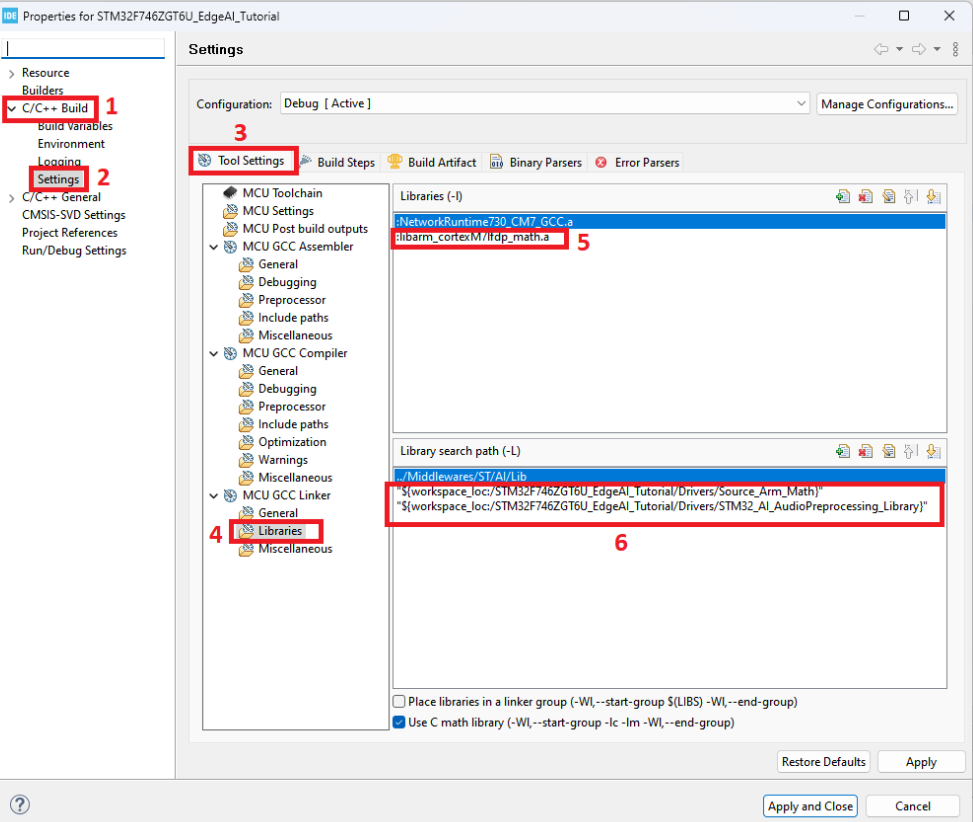
- Đầu tiên cũng trong mục Properties, chúng ta chọn mục “Settings” và tìm đến phần “Libraries” trong mục “MCU GCC Linker” rồi kiểm tra lại các đường dẫn và phần Include (“-I”) đã đầy đủ như hình chưa:

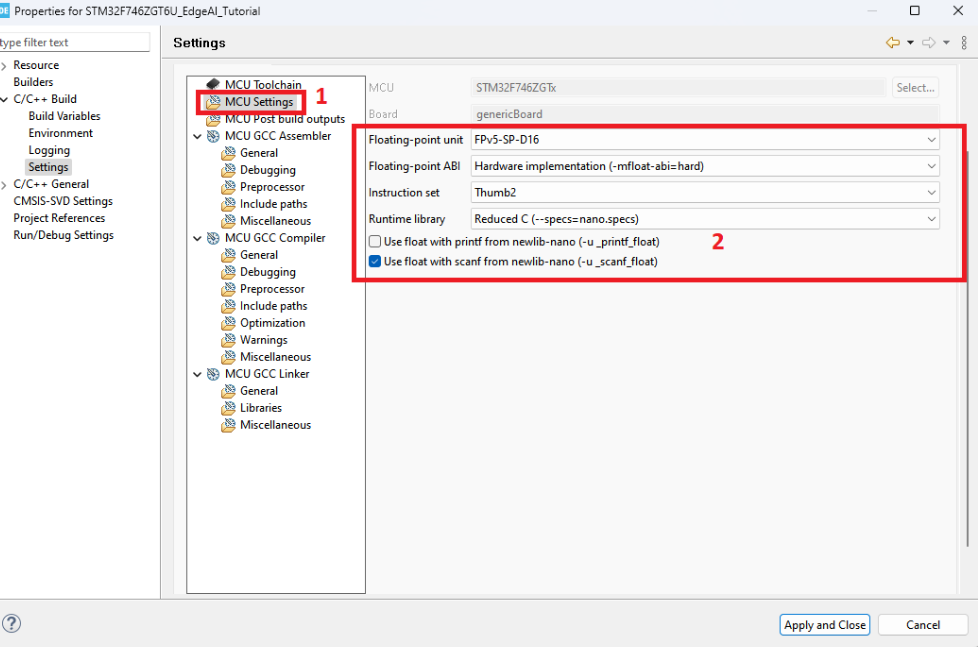
- Kiểm tra các thiết lập về bộ xử lý dấu phẩy động (FPU) vì việc xử lý các con số trong mô hình học sâu yêu cầu tính toán trên số thực:

4. Nhúng mô hình AI
- Đến đây chúng ta đã cấu hình/thiết lập xong các ngoại vi phần cứng và các thư viện hỗ trợ. Tiếp theo chúng ta đến phần viết các mã chương trình nhúng.
- Đầu tiên, khi sử dụng gói X-CUBE-AI thì IDE sẽ tự sinh ra 2 lệnh “MX_X_CUBE_AI_Init();” và “MX_X_CUBE_AI_Process();”. Chúng ta cần phải bỏ 2 dòng lệnh này đi và viết lại chúng sau theo các hướng dẫn của ST. (*Thực tế, chúng ta vẫn có thể dùng các hàm có sẵn trong file “app_x-cube-ai.c” bằng cách viết định nghĩa hàm cho hàm “acquire_and_process_data” và truyền con trỏ dữ liệu input vào hàm đó*). Để bỏ 2 hàm được sinh ra trên, ta lại mở giao diện của CubeMX (nhấn đúp vào file có đuôi “.ioc”), chọn “Project Management” rồi chọn mục “Advanced Settings”. Ở đây chúng ta thấy có rất nhiều tùy chọn nâng cao như kiểm soát các “Driver” hay thiết lập “Visibility” của một hàm được sinh ra bởi IDE.
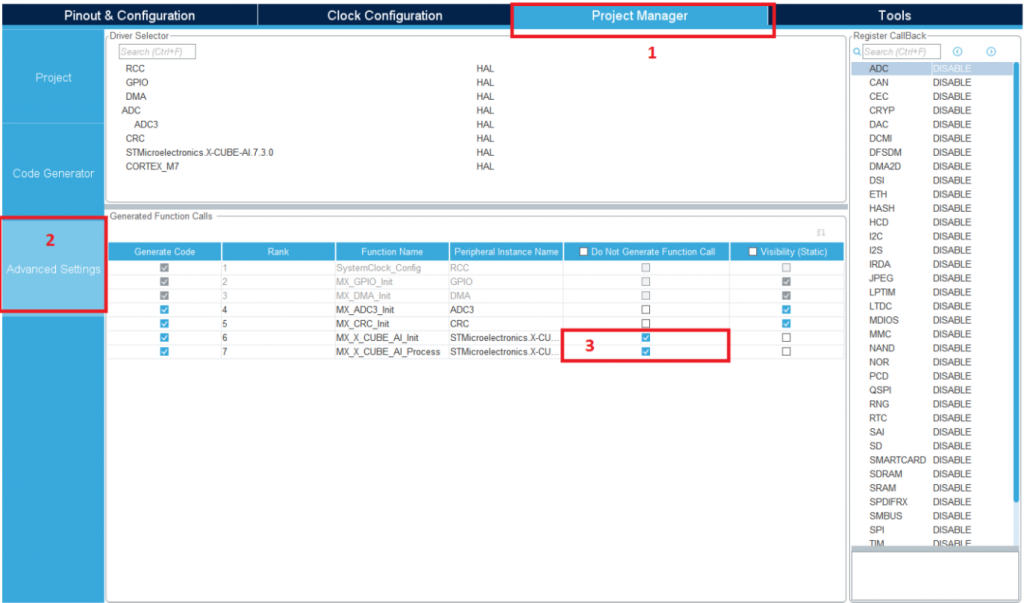

- Đến đây, ta đã có thể bắt đầu viết phần mã nhúng. Tuy nhiên để viết và hiểu được các đoạn mã nhúng, các bạn nên đọc thêm phần tài liệu của ST cho gói X-CUBE-AI.
- Thông thường, STM32CubeIDE sẽ cài đặt gói X-CUBE-AI vào trong thư mục User. Các bạn theo đường dẫn sau : “C:\Users\<user>\STM32Cube\Repository\Packs\STMicroelectronics\X-CUBE-AI\7.3.0\Documentation”.
- Trong thư mục trên chứa toàn bộ thông tin cho gói X-CUBE-AI:
- Giới thiệu về các kiểu dữ liệu và các file chứa tham số mô hình
- Hướng dẫn cách viết hoặc sử dụng các hàm API
- Hướng dẫn viết 1 chương trình để chạy một network
- Hướng dẫn cách đọc lỗi khi thực thi mô hình AI
- Hướng dẫn cách lấy các tham số trong lúc chạy để dùng vào việc khác
- Ngoài ra có một số tính năng nâng cao như thiết lập thêm các lớp tuỳ chọn vào mô hình sẵn có hay cách để di chuyển vùng nhớ chứa các tham số cho mô hình vào vị trí tùy chọn (điều này cho phép tải và cập nhật vùng nhớ chứa mô hình với cấu trúc khác khi cần nâng cấp hoặc thay đổi mô hình).
- Trong phạm vi bài hướng dẫn này, các bạn chỉ cần đọc 2 mục chủ yếu là: “api_break” và “embedded_client_api”. Đặc biệt là tìm hiểu về các hàm “aiInit” và “aiRun” trong hai file trên.
- Đầu tiên ta phải khai báo các file header của các thư viện cũng như các biến cần sử dụng cho mô hình AI. Sau đó, bạn bấm Build và xem thử có lỗi không, nếu có lỗi cần kiểm tra lại các bước setup thư viện và đường dẫn ở bước 3:
|
1 2 3 4 5 6 7 8 9 10 |
/* USER CODE BEGIN Includes */ #include "stdlib.h" #include "string.h" #include "stdio.h" #include "arm_math.h" #include "math_helper.h" #include "feature_extraction.h" #include "network.h" #include "network_data.h" /* USER CODE END Includes */ |
- Tiếp theo cần define các giá trị cần sử dụng trong quá trình tiền xử lý âm thanh (lưu ý là các define này không phải dùng để thiết lập cho mô hình AI mà là dùng trong quá trình biến đổi một mẫu âm thanh gồm 16896 giá trị ở miền thời gian thành một ảnh có kích thước 30×32 làm đầu vào cho mô hình AI – các bạn đọc thêm ở mục Tham khảo [8] hoặc tìm hiệu về xử lý tín hiệu số, biến đổi Fourier để rõ hơn)
|
1 2 3 4 5 6 7 |
#define HOPLENGTH 512 #define FILL_BUFFER_SIZE 1024 #define NFFT 1024 #define NMELS 30 #define ADC_BUF_LEN 16896 #define SPECTROGRAM_ROWS NMELS #define SPECTROGRAM_COLS 32 |
- Tiếp theo ta khai báo các biến dành cho tiền xử lý âm thanh và xử lý mô hình. Các bạn chú ý đến các cụm từ “AI_NETWORK_IN_1_SIZE”, “AI_NETWORK_OUT_1_SIZE”, đây là các define chứa giá trị là kích thước đầu vào và ra của mô hình. Các define này nằm trong file “network_data_params.h” khi khởi tạo mạng ở giao diện CubeMX:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
volatile uint8_t Inference_Mode = 0; //Indicate if all the data is transferred to be inference AI_ALIGNED(32) static ai_float aSpectrogram[AI_NETWORK_IN_1_SIZE]; static float32_t aColBuffer[SPECTROGRAM_ROWS]; float32_t aWorkingBuffer1[NFFT]; static arm_rfft_fast_instance_f32 S_Rfft; static MelFilterTypeDef S_MelFilter; static SpectrogramTypeDef S_Spectr; static MelSpectrogramTypeDef S_MelSpectr; uint16_t ADC_buffer[ADC_BUF_LEN]; uint32_t ColIndex=0; float32_t pBuffer[FILL_BUFFER_SIZE]; static ai_handle network = AI_HANDLE_NULL; AI_ALIGNED(32) static ai_u8 activations[AI_NETWORK_DATA_ACTIVATIONS_SIZE]; AI_ALIGNED(32) static ai_float out_data[AI_NETWORK_OUT_1_SIZE]; static ai_buffer *ai_input; static ai_buffer *ai_output; |
- Bây giờ các bạn viết các hàm để khởi tạo và chạy mô hình:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
void AI_Init(void) { /* Create and initialize the c-model */ const ai_handle acts[] = { activations }; ai_network_create_and_init(&network, acts, NULL); /* Retrieve pointers to the model's input and outputs */ ai_input = ai_network_inputs_get(network, NULL); ai_output = ai_network_outputs_get(network, NULL); } void AI_Run(const void *in_data, void *out_data) { /* Update the data */ ai_input[0].data = AI_HANDLE_PTR(in_data); ai_output[0].data = AI_HANDLE_PTR(out_data); /* Perform interference */ ai_network_run(network, &ai_input[0], &ai_output[0]); } |
- Bây giờ chúng ta viết thêm một số hàm hỗ trợ cho việc xử lý tín hiệu âm thanh đầu vào như sau (Phần này yêu cầu sự hiểu biết về xử lý tín hiệu số còn nếu mạng nơron của các bạn xử lý một tín hiệu khác không cần việc biến đổi này thì có thể bỏ qua các hàm xử lý này):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 |
/* USER CODE BEGIN 4 */ static void Preprocessing_Init(void) { /* Init RFFT */ arm_rfft_fast_init_f32(&S_Rfft, 1024); /* Init Spectrogram */ S_Spectr.pRfft = &S_Rfft; S_Spectr.Type = SPECTRUM_TYPE_POWER; S_Spectr.pWindow = (float32_t *) hannWin_1024; S_Spectr.SampRate = 16000; S_Spectr.FrameLen = 1024; S_Spectr.FFTLen = 1024; S_Spectr.pScratch = aWorkingBuffer1; /* Init Mel filter */ S_MelFilter.pStartIndices = (uint32_t *) melFiltersStartIndices_1024_30; S_MelFilter.pStopIndices = (uint32_t *) melFiltersStopIndices_1024_30; S_MelFilter.pCoefficients = (float32_t *) melFilterLut_1024_30; S_MelFilter.NumMels = 30; /* Init MelSpectrogram */ S_MelSpectr.SpectrogramConf = &S_Spectr; S_MelSpectr.MelFilter = &S_MelFilter; } //-----------Mảng MelSpectrogram 30x32-----// void Mel_array() { for (ColIndex=0; ColIndex<SPECTROGRAM_COLS; ColIndex++) { for(uint16_t i=0; i<1024; i++) pBuffer[i]=(ADC_buffer[ColIndex*HOPLENGTH+i]-2047.0)/2047.0; MelSpectrogramColumn(&S_MelSpectr, pBuffer, aColBuffer); for (uint32_t j = 0; j < NMELS; j++) { aSpectrogram[j * SPECTROGRAM_COLS + ColIndex] = aColBuffer[j]; } } } static void PowerTodB(float32_t *pSpectrogram) { float32_t max_mel_energy = 0.0f; uint32_t i; /* Find MelEnergy Scaling factor */ for (i = 0; i < NMELS * SPECTROGRAM_COLS; i++) { max_mel_energy = (max_mel_energy > pSpectrogram[i]) ? max_mel_energy : pSpectrogram[i]; } /* Scale Mel Energies */ for (i = 0; i < NMELS * SPECTROGRAM_COLS; i++) { pSpectrogram[i] /= max_mel_energy; } /* Convert power spectrogram to decibel */ for (i = 0; i < NMELS * SPECTROGRAM_COLS; i++) { pSpectrogram[i] = 10.0f * log10f(pSpectrogram[i]); } /* Threshold output to -80.0 dB */ for (i = 0; i < NMELS * SPECTROGRAM_COLS; i++) { pSpectrogram[i] = (pSpectrogram[i] < -80.0f) ? (-80.0f) : (pSpectrogram[i]); } } /* ... Các hàm aiInit() và aiRun() ... */ /* USER CODE END 4 */ |
- Bây giờ ta cần phải viết hàm nhận ngắt Full-Transfer cho ngoại vi ADC ở chế độ DMA:
|
1 2 3 4 5 6 7 8 9 10 |
/* USER CODE BEGIN 0 */ void HAL_ADC_ConvCpltCallback(ADC_HandleTypeDef* hadc) { if (hadc == &hadc3) { //Biến thông báo nhận đủ 16896 dữ liệu để thực hiện Inference trên mô hình Inference_Mode = 1; } } /* USER CODE END 0 */ |
- Tiếp theo đó là viết code cho hàm “int main()”:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
/* USER CODE BEGIN 2 */ AI_Init(); Preprocessing_Init(); HAL_ADC_Start_DMA(&hadc3, (uint32_t *)ADC_buffer, ADC_BUF_LEN); /* USER CODE END 2 */ /* Infinite loop */ /* USER CODE BEGIN WHILE */ while (1) { if (Inference_Mode == 1) { Mel_array(); PowerTodB(aSpectrogram); AI_Run(&aSpectrogram, &out_data); memset(ADC_buffer, 0, ADC_BUF_LEN*2); Inference_Mode = 0; HAL_ADC_Start_DMA(&hadc3, (uint32_t *)ADC_buffer, ADC_BUF_LEN); } /* USER CODE END WHILE */ /* USER CODE BEGIN 3 */ } |
- Đến đây bạn có thể build chương trình xem có lỗi không. Nếu không lỗi có thể dùng chế độ debug để xem sự thay đổi các kết quả đầu vào và đầu ra như hình sau:
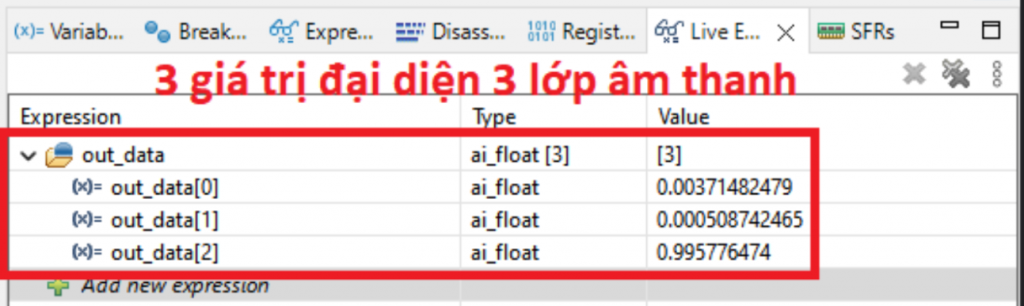

- Nếu cộng tổng 3 giá trị lại thì sẽ được giá trị xấp xỉ 1 hoặc 1 là OK.
- File code “main.c” được upload tại mục tham khảo [9].
5. Kết luận
- Gói phần mềm X-CUBE-AI
Với sự hỗ trợ của gói phần mềm X-CUBE-AI đến từ hãng STMicroelectronics thì việc triển khai một mạng nơron trên các dòng VĐK STM32 rõ ràng không phải điều quá khó. Điều quan trọng ở việc nhúng mô hình học sâu vào các dòng vi điều khiển với hiệu năng và bộ nhớ hạn chế là việc tối ưu, cân bằng giữa hiệu năng, bộ nhớ và độ chính xác.
- Tài nguyên và tiềm năng
Và thậm chí nếu dựa vào một số tham số khi chuyển đổi các mô hình học sâu sang c-model thì ta còn thấy được tiềm năng xử lý các mô hình học sâu ở thời gian thực. Ví dụ khi ta nhìn ở giao diện CubeMX, ta có thể thấy được một tham số là “Complexity: <…> MACC” thì đây chính là tham số chỉ độ phức tạp của mô hình (dựa trên số lớp và số tham số cũng như số phép tính phải làm ở các lớp của mô hình học sâu). Dựa trên tài liệu tham khảo [10] mục 4.5.1, ta thấy 1 MACC cần khoảng 6 chu kì máy đối với dòng Cortex-M7 và khoảng 9 chu kì máy đối với dòng Cortex-M4/M33. Từ đây ta tính được tốc độ khi thực thi mô hình như sau:
| Tần số CPU (MHz) | 184.5 |
| Độ phức tạp (MACC) | 6276960 |
| Số chu kì máy/MACC | 6 |
| Thời gian thực thi (s) | 0.2 |
Chưa kể, cả chương trình trên chỉ chiếm 48.07% RAM (trên tổng 320KB) và 26.38% FLASH (trên tổng 1024KB) của kit STM32F746-DISCOVERY, điều này cho phép chúng ta mở rộng firmware cho nhiều tác vụ khác và cả việc update mô hình/firmware mới từ xa.
Chúc các bạn thành công và đón chờ các bài viết khác liên quan đến Edge AI trên STM32!
Nhóm nghiên cứu EdgeAI
Ng.Q.Phuong, T.T.M.Duyen, H.V.Thach