



Dựa theo phương thức học thì các thuật toán Machine Learning có thể chia ra làm 3 loại: Supervised Learning (Học có giám sát), Unsupervised Learning (Học không giám sát) và Reinforcement learning (Học củng cố). Supervised Learning là thuật toán dự đoán đầu ra của một dữ liệu mới dựa trên các cặp dữ liệu đầu vào cho trước. Unsupervised Learning chỉ có dữ liệu đầu vào và được áp dụng cho các trường hợp không dự đoán được câu trả lời chính xác cho mỗi dữ liệu đầu vào. Trong bài giới thiệu này sẽ không đề cập đến Reinforcement learning mà chỉ chú trọng vào Supervised Learning và Unsupervised Learning. Dưới đây là 10 thuật toán về Supervised Learning và Unsupervised Learning:
1.Supervised Learning
Cây quyết định là một công cụ hỗ trợ quyết định sử dụng biểu đồ dạng cây hoặc mô hình của các quyết định và kết quả có thể xảy ra của chúng, bao gồm kết quả sự kiện ngẫu nhiên, chi phí tài nguyên và tiện ích.
Cây quyết định (Decision Trees)
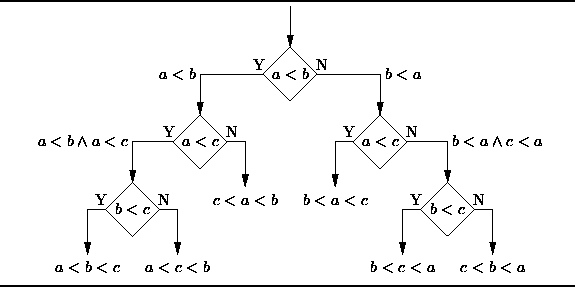

Cây quyết định là số câu hỏi Có/Không tối thiểu mà người ta phải hỏi, để đánh giá xác suất đưa ra quyết định đúng. Cây quyết định là một phương pháp mà nó cho phép bạn tiếp cận vấn đề một cách có cấu trúc và có hệ thống để đạt được một kết luận hợp lý.
Sự phân lớp Naïve Bayes
Nhóm phân loại Naïve Bayes là một nhóm các sự phân loại xác suất đơn giản dựa trên việc áp dụng định lý Bayes với các giả định độc lập giữa các tính năng.
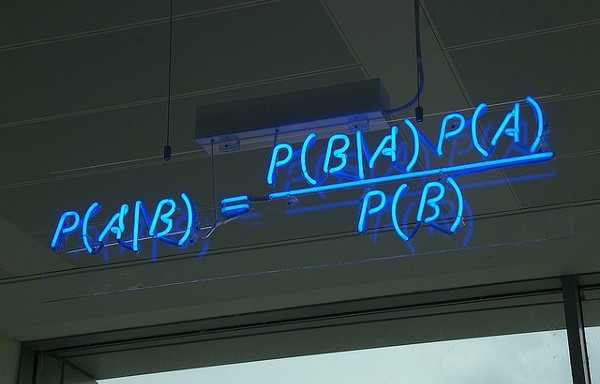

-
Đánh dấu email là spam hoặc không phải spam
-
Phân loại bài viết tin tức về công nghệ, chính trị hoặc thể thao
-
Kiểm tra một đoạn văn thể hiện cảm xúc tích cực, hoặc cảm xúc tiêu cực?
-
Được sử dụng cho phần mềm nhận diện khuôn mặt
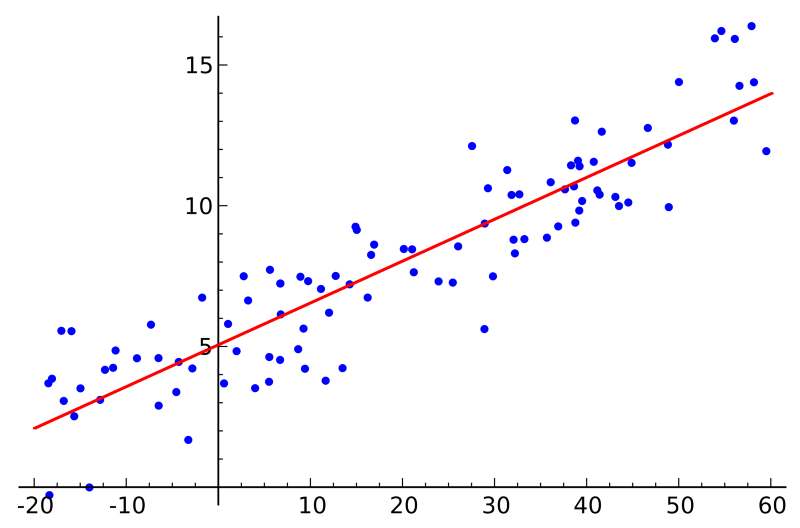

Phương pháp tuyến tính đề cập đến loại mô hình đang sử dụng để phù hợp với dữ liệu, trong khi phép bình phương nhỏ nhất đề cập đến loại số liệu lỗi đang giảm thiểu.

Một vài ví dụ thực tế:
- Điểm tín dụng
- Đo lường tỷ lệ thành công của các chiến dịch tiếp thị
- Dự đoán doanh thu của một sản phẩm nhất định
- Sẽ có một trận động đất vào một ngày cụ thể?
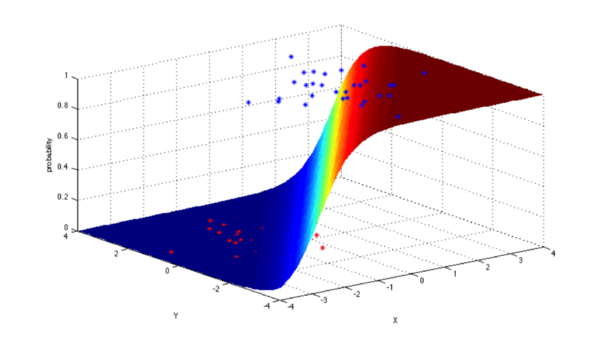
Support Vector Machines (SVM)
SVM là thuật toán phân loại nhị phân. Với một bộ điểm 2 loại ở vị trí N chiều, SVM tạo ra một siêu mặt phẳng (N – 1) chiều để tách các điểm đó thành 2 nhóm. Giả sử phân chia tập các quả bóng xanh và đỏ đặt trên một mặt phẳng mà có thể phân chia tuyến tính. Nếu các quả bóng phân bố không quá đan xen vào nhau, SVM sẽ tìm ra một mặt phẳng tách những quả bóng này thành 2 loại và nằm cách xa nhau càng tốt.
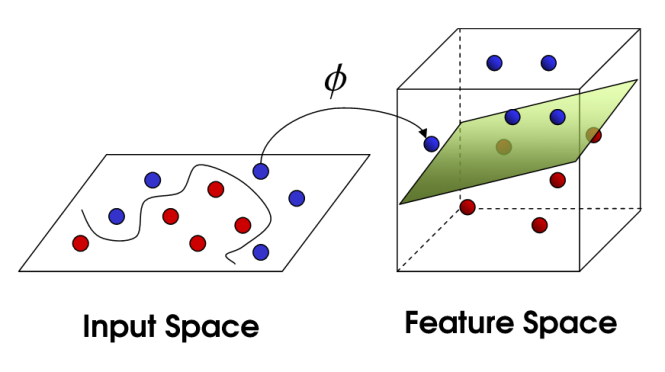

Xét về quy mô, một số vấn đề lớn nhất đã được giải quyết bằng cách sử dụng SVM (với việc thực hiện sửa đổi phù hợp) là quảng cáo hiển thị, phát hiện giới tính dựa trên hình ảnh, phân loại hình ảnh có quy mô lớn…
Ensemble Methods
Ensemble Methods là kỹ thuật tạo ra nhiều mô hình và sau đó kết hợp chúng lại để đưa ra kết quả. Một vài phương pháp Ensemble Methods được biết đến rộng rãi : voting, stacking, bagging and boosting.

2.Unsupervised Learning
Cho một tập hợp điểm dữ liệu và gộp những điểm đó vào từng nhóm (cluster). Mỗi nhóm chứa những điểm dữ liệu giống nhau, ngược lại những điểm ở khác nhóm thì khác nhau.
Clustering Algorithms
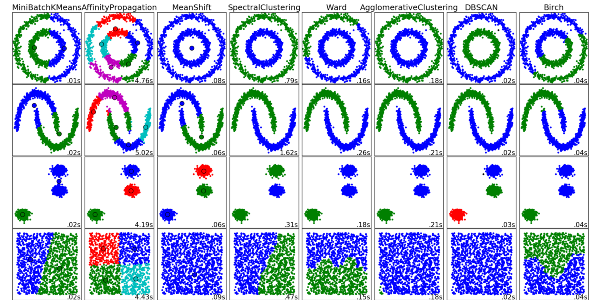

Một số thuật toán Clustering:
- Centroid-based algorithms
- Connectivity-based algorithms
- Density-based algorithms
- Probabilistic
- Dimensionality Reduction
- Neural networks / Deep Learning
Principal Component Analysis
Là một thuật toán thống kê sử dụng phép biến đổi trực giao để biến đổi một tập hợp dữ liệu từ một không gian nhiều chiều sang một không gian mới ít chiều hơn (2 hoặc 3 chiều) nhằm tối ưu hóa việc thể hiện sự biến thiên của dữ liệu.
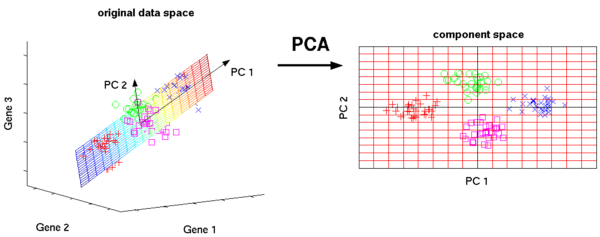

Một số ứng dụng của Principal Component Analysis: nén dữ liệu, đơn giản hóa dữ liệu.
Singular Value Decomposition
Trong phương pháp SVD, mọi ma trận, không nhất thiết là vuông, đều có thể được phân tích thành tích của ba ma trận đặc biệt.
M: input data matrix
U: left singular vectors
V: right singular vectors
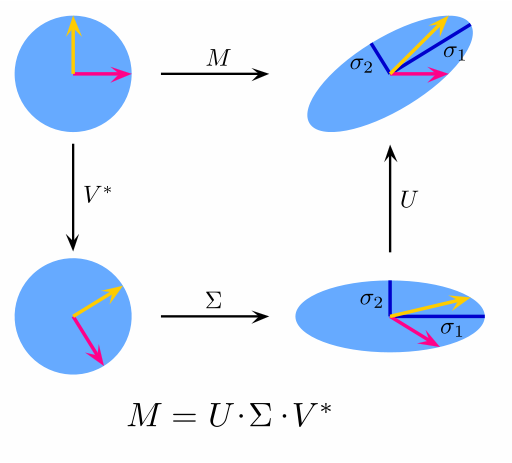

Phương pháp PCA thực chất là một ứng dụng của SVD. Thuật toán nhận diện khuôn mặt đầu tiên sử dụng cả 2 phương pháp PCA và SVD để hiện ra những khuôn mặt như một sự kết hợp tuyến tính của các “eigenfaces”.
Independen Component Analysis
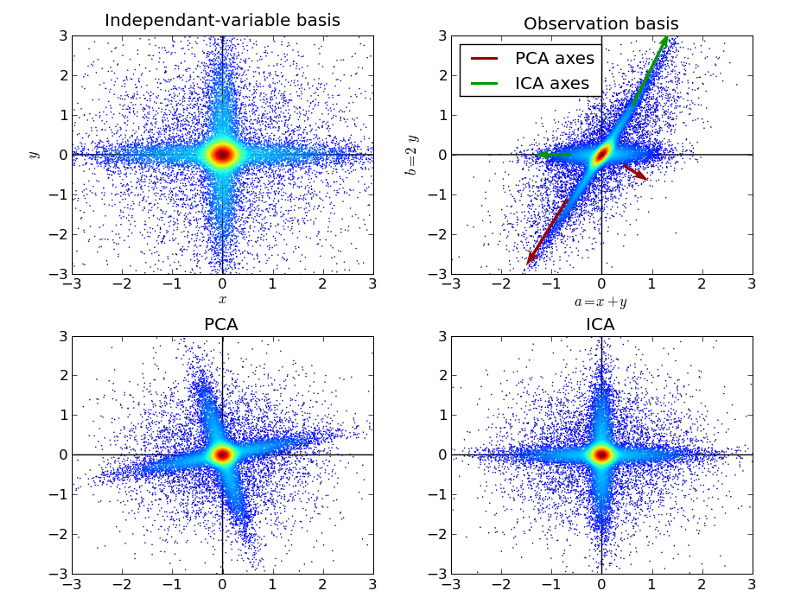

ICA có thể được ứng dụng vào xử lý tín hiệu sinh học, phân tách tín hiệu âm thanh truyền thông, chuẩn đoán lỗi, trích đặc trưng, phân tích kế toán, và nhiều ứng dụng khác đang được phát triển.
ICA liên quan đến PCA nhưng nó là một kỹ thuật mạnh hơn nhiều do có khả năng tìm ra các yếu tố bên dưới của các nguồn trong khi những phương pháp trước đều thất bại hoàn toàn.